geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
OpenAI Unveils Revolutionary Image Generation in ChatGPT: A New Era for Visual AI
Updated: March 27 2025 19:40
OpenAI has launched 4o image generation capabilities directly within ChatGPT. This significant upgrade represents not just an incremental improvement, but a fundamental leap forward in how AI can assist with visual creation. The new feature, which integrates seamlessly with ChatGPT's powerful language capabilities, promises to transform how creators, educators, small business owners, and students interact with artificial intelligence tools.
Unlike traditional diffusion-based image generators (including OpenAI's own DALL-E models), 4o's image generation capability represents a fundamental architectural shift. The new system is built as a truly native multimodal model - meaning it's not just calling out to a separate image generation system but is generating images as part of its core understanding of the world.
OpenAI has been working on this feature for two years, beginning with a scientific question: what would native support for image generation look like in a model as powerful as GPT-4? The result is nothing short of remarkable - a truly integrated multimodal AI system that can understand context across text and images, generating visuals with unprecedented quality and accuracy.
"This is really something that we have been excited about bringing to the world for a long time," said Sam Altman, CEO of OpenAI, during the launch presentation. "We think that if we can offer image generation like this, creatives, educators, small business owners, students - way more will be able to use this and do all kinds of new things with AI that they couldn't before."
What makes this launch particularly exciting is that it's not just about creating pretty pictures. The new image generation capabilities represent a significant advancement in AI's ability to understand and execute complex visual tasks with remarkable precision.
Perfect Text Rendering and Contextual Understanding
Perhaps the most immediately noticeable improvement is 4o's exceptional ability to render text correctly. Previous image generation models (including DALL-E 3) notoriously struggled with text, often producing gibberish when asked to include writing in images. The 4o model can create perfect text rendering, accurately displaying paragraphs, labels, and signage. During demonstrations, the OpenAI team showed how the model could create images with flawless text integration, making it ideal for creating educational materials, infographics, memes, and more. See the following impressive demos:
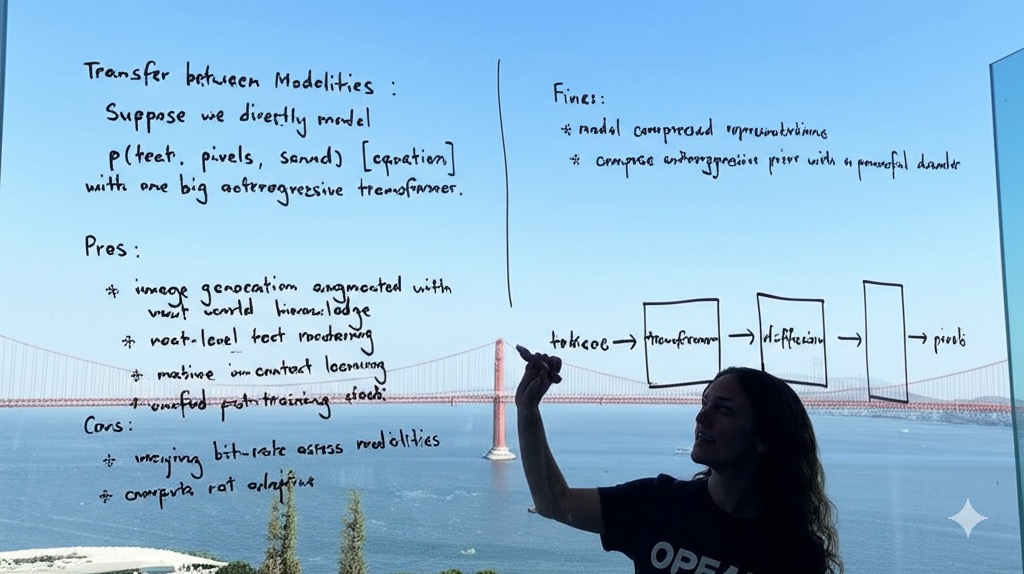
A wide image taken with a phone of a glass whiteboard, in a room overlooking the Bay Bridge. The field of view shows a woman writing, sporting a tshirt wiith a large OpenAI logo. The handwriting looks natural and a bit messy, and we see the photographer's reflection.
The text reads:
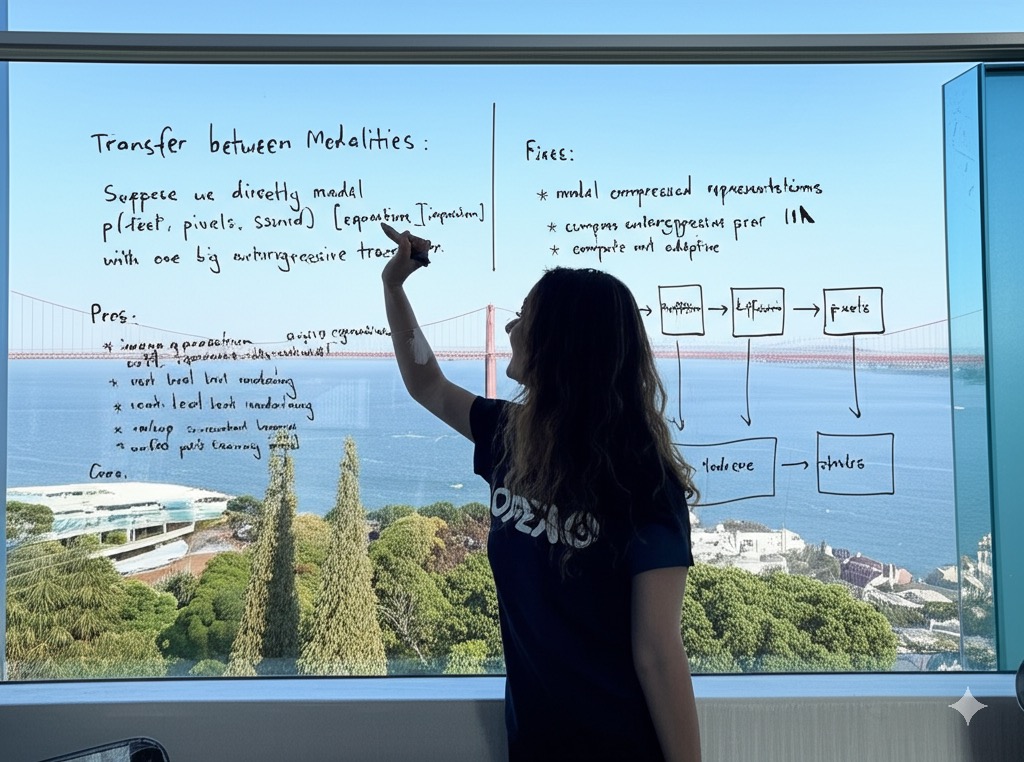
(left) "Transfer between Modalities:
Suppose we directly model p(text, pixels, sound) [equation] with one big autoregressive transformer.
Pros: * image generation augmented with vast world knowledge * next-level text rendering * native in-context learning * unified post-training stack
Cons: * varying bit-rate across modalities * compute not adaptive"
(Right) "Fixes: * model compressed representations * compose autoregressive prior with a powerful decoder"
On the bottom right of the board, she draws a diagram: "tokens -> [transformer] -> [diffusion] -> pixels"
selfie view of the photographer, as she turns around to high five him
To compare, here is what Google Gemini 2.0 Flash (Image Generation) generated with the same prompt:
The model displays an almost uncanny ability to follow complex instructions precisely. While other models might handle 5-8 objects in a scene, GPT-4o can manage up to 10-20 different objects with correct relationships between them. This level of control makes it vastly more useful for practical applications. In one demo, it created a point-of-view image based on detailed specifications, correctly interpreting what should be in focus and how the perspective should be framed. This level of control gives users unprecedented ability to realize their creative visions.
Because image generation is now native to the model, users can have natural conversations about images - making progressive modifications, refinements, and transformations. This creates a much more intuitive editing experience than previous systems allowed.
I'm opening a traditional concept restaurant in Marin called Haein. It focuses on Korean food cooked with organic, farm-fresh ingredients, with a rotating menu based on what's seasonal. I want you to design an image - a menu incorporating the following menu items - lean into the traditional/rustic style while keeping it feeling upscale and sleek. Please also include illustrations of each dish in an elegant, peter rabbit style. Make sure all the text is rendered correctly, with a white background.
(Top)
Doenjang Jjigae (Fermented Soybean Stew) – $18 House-made doenjang with local mushrooms, tofu, and seasonal vegetables served with rice.
Galbi Jjim (Braised Short Ribs) – $34 Slow-braised local grass-fed beef ribs with pear and black garlic glaze, seasonal root vegetables, and jujube.
Grilled Seasonal Fish – Market Price ($22-$30) Whole or fillet of local, sustainable fish grilled over charcoal, served with perilla leaf ssam and house-made sauces.
Bibimbap – $19 Heirloom rice with a rotating selection of farm-fresh vegetables, house-fermented gochujang, and pasture-raised egg.
Bossam (Heritage Pork Wraps) – $28 Slow-cooked pork belly with napa cabbage wraps, oyster kimchi, perilla, and seasonal condiments.
Rotating flavors based on seasonal fruits and flowers (persimmon, citrus, elderflower, etc.).
Hoddeok (Korean Sweet Pancake) – $9 Pan-fried cinnamon-stuffed pancake with black sesame ice cream.
To compare, here is what Google Gemini 2.0 Flash (Image Generation) generated with the same prompt:
HackerNews users were particularly fascinated by what several described as "reasoning in pixel space." As user 'blixt' commented:
What's important about this new type of image generation that's happening with tokens rather than with diffusion, is that this is effectively reasoning in pixel space. Example: Ask it to draw a notepad with an empty tic-tac-toe, then tell it to make the first move, then you make a move, and so on.
In general, many users were impressed by the leap in capabilities, particularly around text rendering and prompt following:
I've just tried it and oh wow it's really good. I managed to create a birthday invitation card for my daughter in basically 1-shot, it nailed exactly the elements and style I wanted. Then I asked to retain everything but tweak the text to add more details about the date, venue etc. And it did. I'm in shock. Previous models would not be even halfway there.
From Research Project to Powerful Product
Led by Gabriel (Gabe), the lead researcher on the project, the team spent over a year refining the initial research model into a user-friendly product. What began as an exploration yielded exciting "signs of life" that reminded the team of the groundbreaking moments from earlier AI breakthroughs.
"I felt that sense of joy and excitement... I haven't felt for a very long time, maybe even since GPT-2," noted one team member during the presentation.
The early research version showed promise but was still rough around the edges, occasionally making typos and proving somewhat unreliable. The team spent the last year refining the model to make it more accessible and consistent for average users. This accessibility extends beyond just policy decisions. The team emphasized how the tool democratizes creative expression, allowing those without professional artistic skills to visually express their ideas. As one team member put it, "What I love the most about this model is how accessible it is to everyone."
While OpenAI hasn't released detailed technical information, what we know is that the model:
Uses an autoregressive approach - generating images sequentially from top to bottom (rather than creating the entire image at once as diffusion models do)
Integrates deeply with the model's world knowledge and language understanding
Can process both text and image inputs to create coherent outputs
Maintains context and memory across multiple interactions
OpenAI has taken a noteworthy stance with this release, choosing to provide users with a high degree of creative freedom. While ensuring the model doesn't produce offensive content by default, the company is "leaning pretty far into creative freedom" to maximize utility for users.
Limitations and Future Development
OpenAI was refreshingly candid about the model's current limitations, which include:
Occasional cropping issues - Particularly with longer images
Hallucinations - Making up information, especially in low-context prompts
High binding problems - Struggling when handling more than 10-20 distinct concepts
Multilingual text challenges - Non-Latin alphabets can be inaccurate
Editing precision issues - Requests to edit specific portions sometimes lead to unwanted changes
The company has committed to addressing these limitations in future iterations.
Practical Applications Demonstrated
The launch presentation showcased several impressive applications of the new technology:
Photo transformation: Converting a real photo into anime-style art while preserving key features and expressions
Meme creation: Transforming images into humorous memes with perfect text integration
Educational materials: Creating a colorful manga page explaining the theory of relativity with added humor
Custom designs: Generating a trading card featuring a user's pet in a specific style, complete with detailed stats and text
Memorial objects: Combining multiple images into a commemorative coin with precise text placement and transparent background for printing
The demonstrations highlighted the model's ability to maintain consistency across edits and understand context across multiple turns of conversation - making it ideal for iterative creative processes.
However, many HackerNews users pointed out that the technology still works best as a collaborative tool with human guidance:
Automation tools are always more powerful as a force multiplier for skilled users than a complete replacement. (Which is still a replacement on any given task scope, since it reduces the number of human labor hours — and, given any elapsed time constraints, human laborers — needed.)
Performance and Availability
While the new image generation may be slower than previous versions, the quality improvement is described as "unbelievably better" - a tradeoff the team feels is absolutely worth it. They also noted that speed improvements will come over time.
The model was trained in a non-autoregressive way, allowing it to understand both text and multiple images in context and render them harmoniously. This training approach enables the system to create images that reflect a deep understanding of the world, effectively externalizing its knowledge in visual form.
The new image generation capabilities are available immediately in ChatGPT and Sora for Plus and Pro users, with free users gaining access shortly thereafter. API access will follow in the near future. [Update: OpenAI CEO Sam Altman announced the next day that the rollout of ChatGPT’s viral new AI image features to free users would be delayed, citing significantly higher demand than the company expected.]
images in chatgpt are wayyyy more popular than we expected (and we had pretty high expectations).
rollout to our free tier is unfortunately going to be delayed for awhile.
[Update: ChatGPT’s image generation tool has become extremely popular among users. It can transform existing images into multiple styles. One of the available styles, Studio Ghibli, has become the most popular among all. This is not too surprising since the artistic style of the Japanese animation studio’s films has always been known for many years. This is probably the reason why the launch to free users is delayed.]
What makes this development particularly significant is how it transforms AI from a primarily text-based tool into something that can fully engage with the visual dimension of human communication. As one researcher noted during the presentation, we are surrounded by hundreds of images each day - not just aesthetic or beautiful ones, but "workhorse images" created with intent to persuade, inform, and educate.
Create image super-realistic picture of these 4 creatures playing poker on a picnic blanket, zoomed out, in dolores park. photorealistic. The tabby long haired cat is holding a hand; right next to it are 2 tall vertical black chips (with stripes) as it has been raking in the dough. Tabby's pupils are large and cute, and ii looking down and scrutinizing its cards, focused. Derpy black cat went all in. Two dogs are peering over cat's shoulder to see their cards. All cards are face down and of the same back color except for an exposed three of diamonds. small stack of poker chips are in front of each creature, but black cat went all in. the two dogs folded. All chips are from the same set and all cards have same color. photorealistic, shot on iphone, raw format.
To compare, here is what Google Gemini 2.0 Flash (Image Generation) generated with the same prompt: