geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
Robotic Foundation Models: Transforming How Robots Learn and Adapt
AI Summary: Robotic foundation models are revolutionizing robotics by leveraging pre-trained models on vast amounts of weakly labeled web data, fine-tuning or prompting them for specific downstream tasks, and generalizing across multiple domains with minimal task-specific data. Recent advancements have incorporated reinforcement learning (RL) to optimize performance, enabling robots to learn complex tasks like assembly and manipulation, and improving their ability to recover from mistakes through sequential reasoning and embodied chain of thought approaches.
March 30 2025 08:45
Sergey Levine from UC Berkeley recently presented research on robotic foundation models at the University of Toronto Robotics Institute, showcasing how these pre-trained models are revolutionizing robotic learning and capabilities.
Sergey Levine received a BS and MS in Computer Science from Stanford University in 2009, and a Ph.D. in Computer Science from Stanford University in 2014. He joined the faculty of the Department of Electrical Engineering and Computer Sciences at UC Berkeley in fall 2016. His work focuses on machine learning for decision making and control, with an emphasis on deep learning and reinforcement learning algorithms.
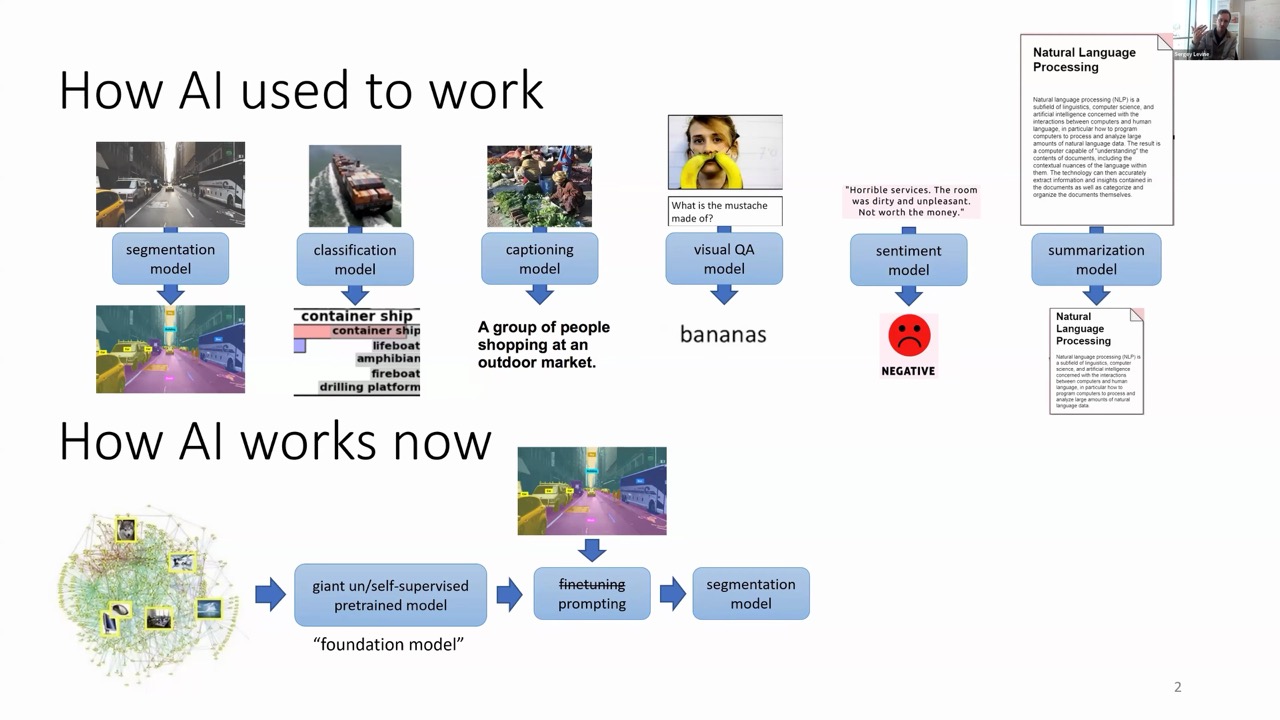
From Specialized Models to Foundation Models
Just five years ago, the AI landscape looked very different. For each specific problem—whether image classification, captioning, or text summarization—researchers would:
Collect large, specialized datasets
Obtain high-quality human-generated labels
Train large models specifically for that application
This labor-intensive approach required rebuilding the wheel for every new task. Today, the paradigm has shifted dramatically toward foundation models, which are:
Pre-trained on vast amounts of weakly labeled web data
Adaptable to downstream tasks through fine-tuning or simple prompting
Capable of generalizing across multiple domains with minimal task-specific data
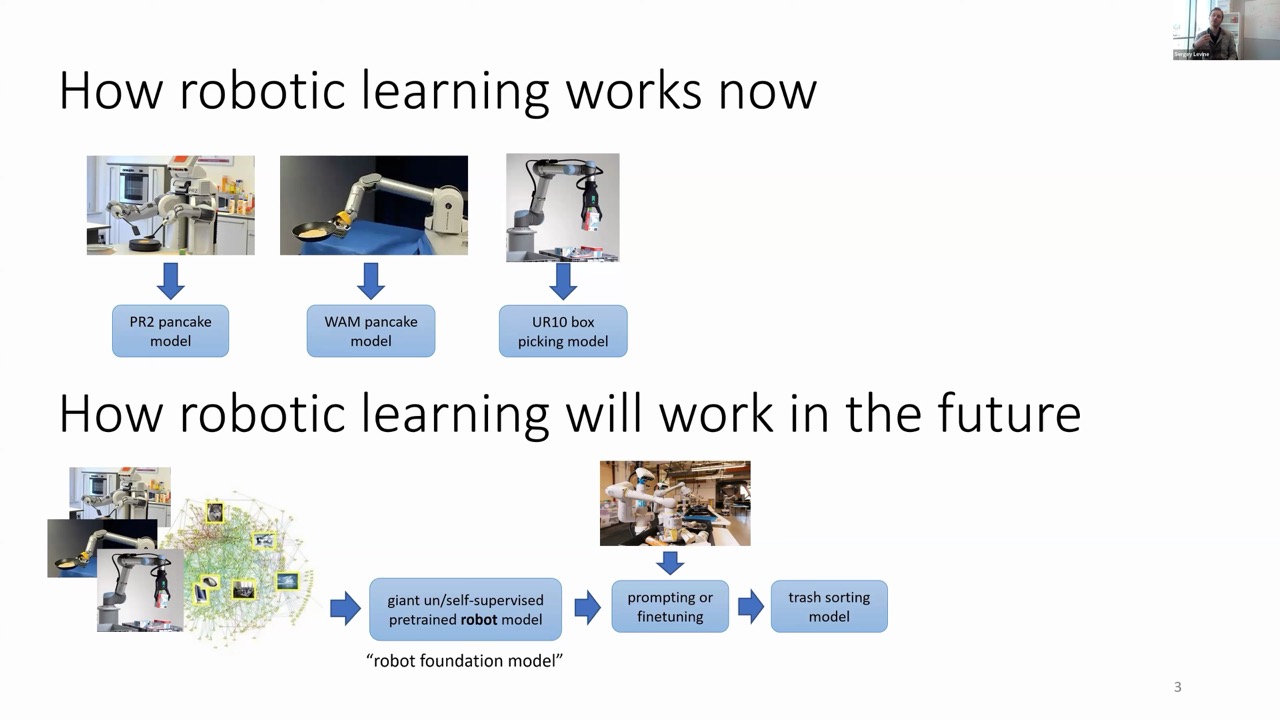
Robotics: Still in the Specialized Model Era
Interestingly, robotics today resembles where vision and NLP were half a decade ago. For each robotic task—like flipping pancakes—engineers typically collect specialized data for that specific task and train highly specialized models. This approach severely limits scalability and broad application.
The vision for the future is clear: robotic foundation models that can handle diverse applications across different robot platforms, which can then be fine-tuned or prompted for specific downstream tasks—just like how GPT or CLIP models work today.
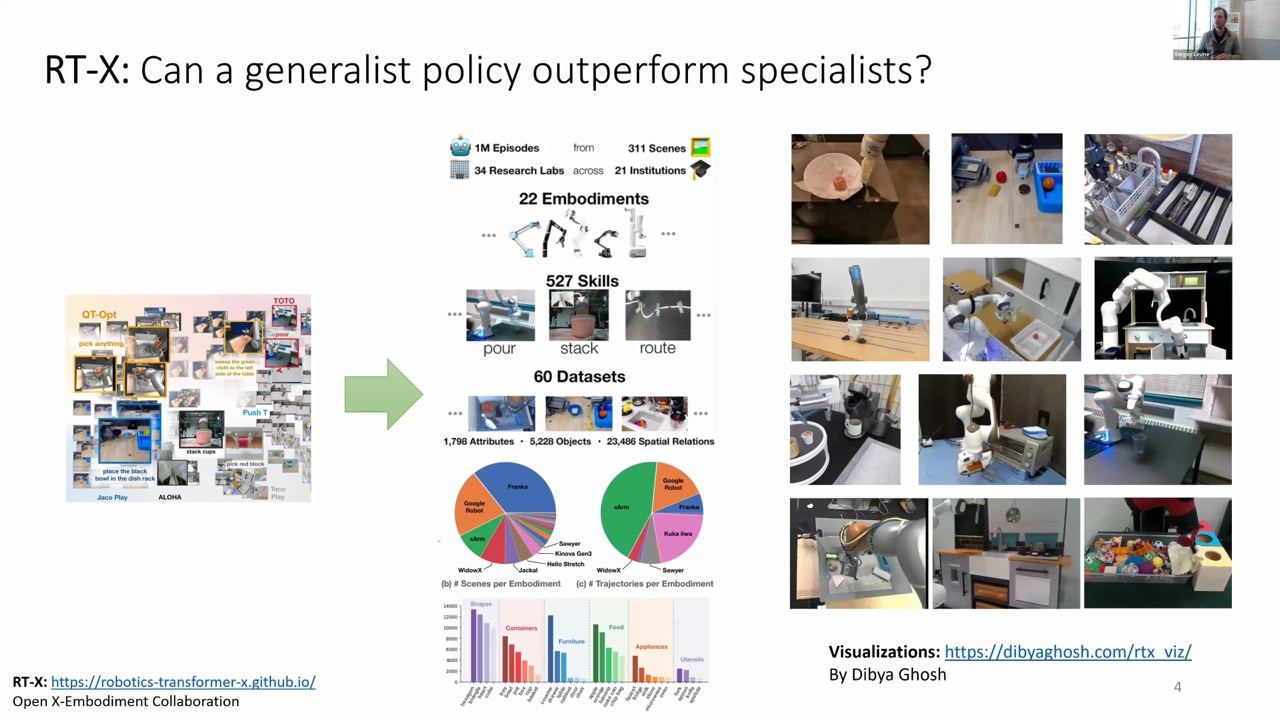
RT-X: Pioneering Cross-Embodiment Learning at Scale
One of the significant turning points in robotic foundation model research was the RT-X project (Open X-Embodiment Collaboration). To explore cross-embodiment learning at scale, the researchers:
Collected data from 34 different research labs
Incorporated 22 different types of robots
Included hundreds of skills across diverse environments
While they limited the scope to single-arm manipulators with parallel jaw grippers, the diversity of data was impressive—featuring different arm types, camera viewpoints, geographic locations, and tasks.
The cross-embodiment model trained on the entire RT-X dataset consistently outperformed specialized models—even on the specialized tasks these models were specifically designed for. On average, the generalist model demonstrated a 50% improvement over domain-specific approaches.
This mirrors what happened in NLP, where generalist language models now routinely outperform specialized models even on specialized tasks.
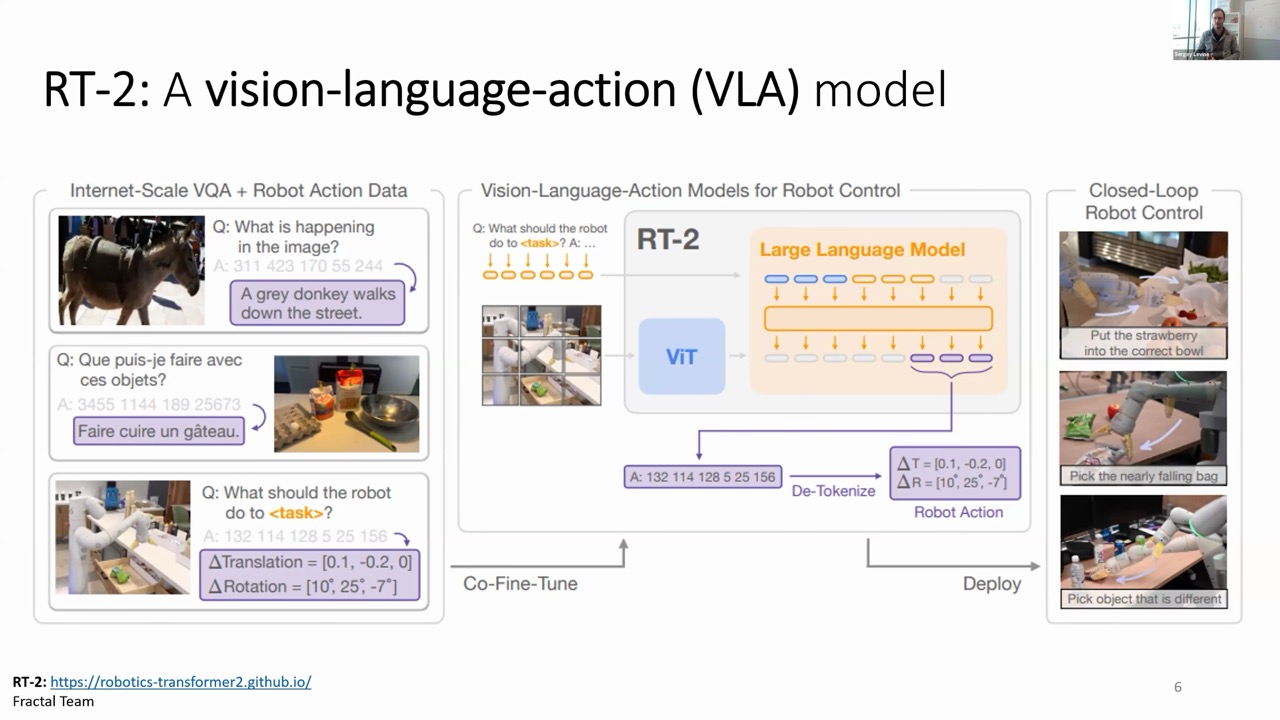
Vision-Language-Action Models: Bridging Visual Understanding and Physical Action
The second critical ingredient for robotic foundation models is the architecture itself. A powerful innovation has been Vision-Language-Action (VLA) models, with RT-2 being the first published VLA model.
RT-2 adapted vision-language models (which accept both image and text inputs) for robotic control. Although the implementation was simple—directly tokenizing robot actions as ASCII numbers and treating it like a visual question-answering problem—it showed impressive results in language-following tasks.
When combined with the RT-X dataset, robots could understand spatial relationships and follow commands like "move objects close to each other"—even when these specific examples weren't in the robot's training data. Cross-embodiment training led to 3x better performance on difficult out-of-distribution commands.
PI-Zero: A True Robot-Centric Foundation Model
Despite these advances, early VLAs had limitations—simple tasks, limited generalization, and architectures not truly optimized for robotics. Enter PI-Zero (Physical Intelligence Zero), launched exactly one year ago to create a truly robot-centric foundation model.
PI-Zero significantly upgraded the VLA approach through:
Diverse data collection: Including seven different robot types (one-arm, two-arm, mobile robots, static robots) with many variations
More sophisticated architecture: Starting with the PolyGemma VLM (combining Gemma language model and CLIP image encoder)
Flow matching for action generation: Using a separate "action expert" with flow matching loss to produce continuous action sequences
Strategic pre-training and post-training: Combining broad pre-training data (10,000+ hours) with high-quality post-training data (1-20 hours) for specific tasks
The model processes multiple camera inputs (base and wrist cameras) and can handle different robot embodiments by coercing them into the same action space (zero-padding if a robot has fewer action dimensions).
Complex Task Mastery: From Box Assembly to Laundry Folding
The PI-Zero model demonstrated remarkable capabilities across challenging tasks:
Box Assembly: Folding a flattened cardboard box with all its flaps—requiring precise manipulation, bracing against the table, and recovering from mistakes.
Table Busing: Cleaning a table by identifying if items are trash (to be thrown away) or dishes (to be placed in a busing bin).
Laundry Handling: Taking crumpled clothing from a bin or dryer, flattening it, and folding it neatly—even recovering when humans intentionally interfere with the task.
What makes these demonstrations particularly impressive is how the robot recovers from mistakes. The combination of broad pre-training data (which includes many mistakes and recovery strategies) with high-quality post-training data enables robust performance.
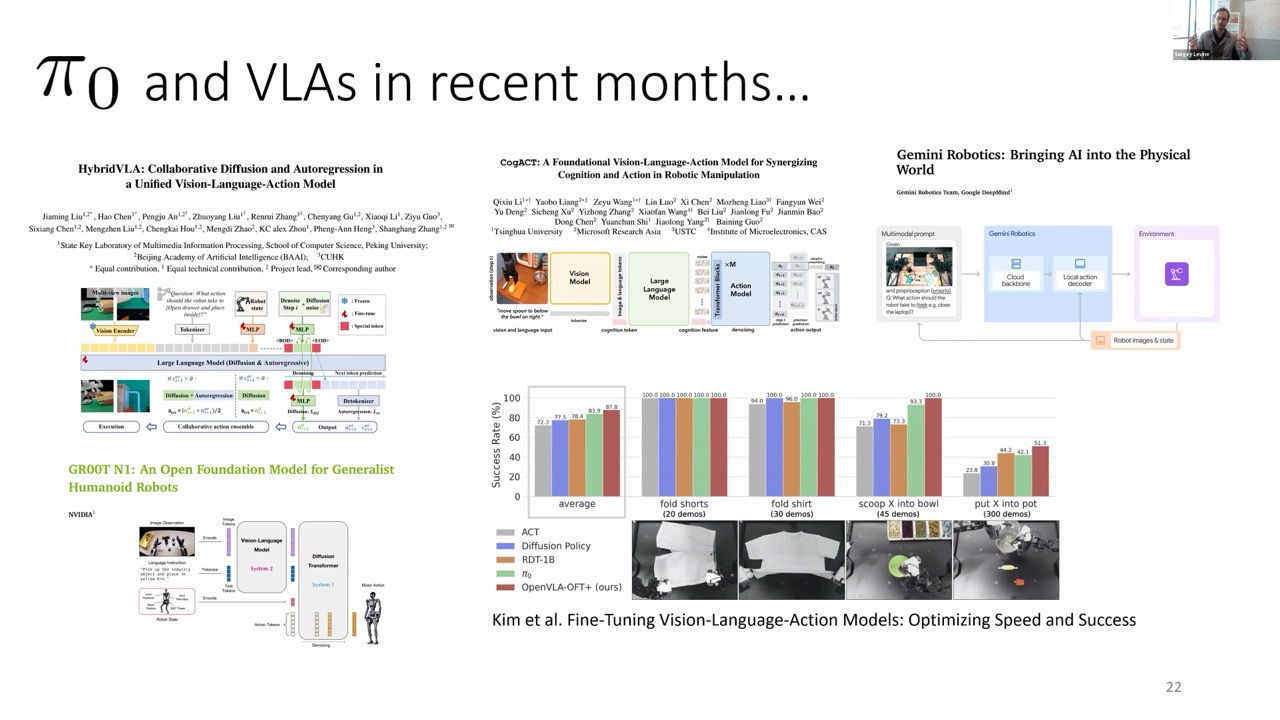
Since PI-Zero's release in October 2023, there has been an explosion in VLA research, with many trends following similar approaches—combining diffusion models with VLMs and incorporating cross-embodiment training.
Enhancing VLAs with Sequential Reasoning
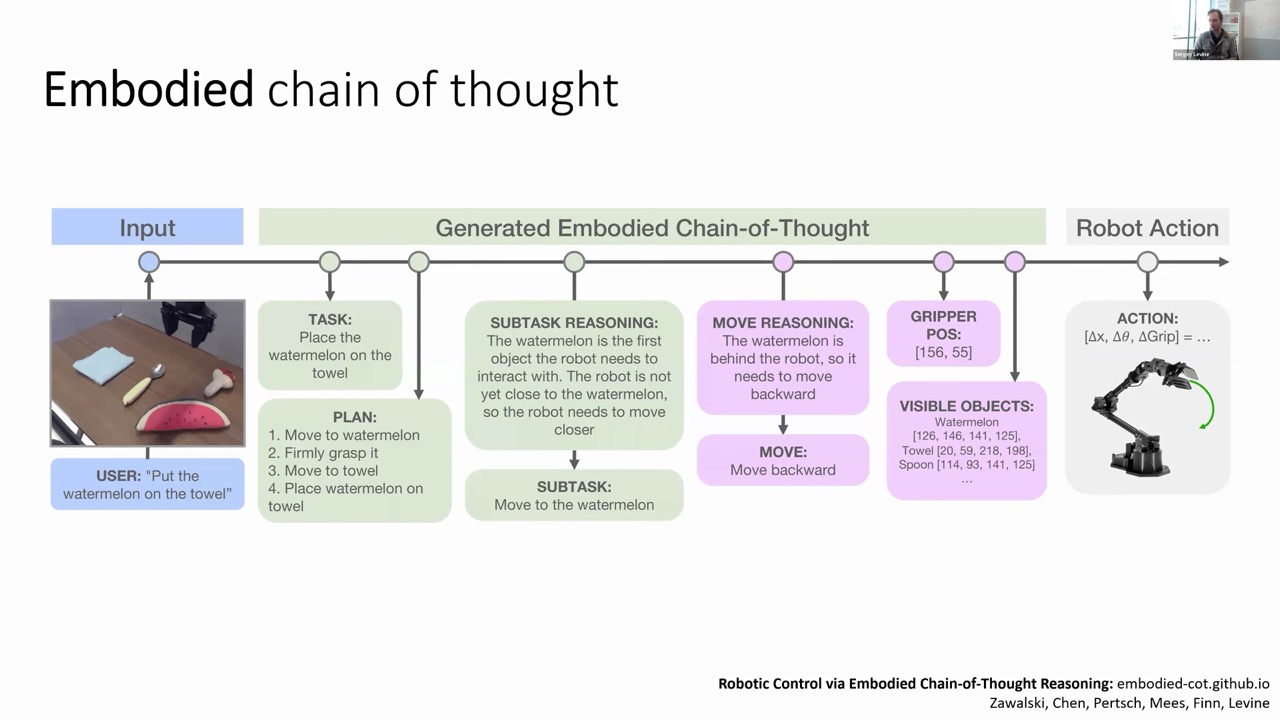
While PI-Zero showed impressive capabilities, more complex tasks require advanced reasoning. The researchers developed an "Embodied Chain of Thought" approach that incorporates sequential reasoning into VLAs.
Instead of directly mapping from language commands and images to actions, the model performs intermediate reasoning steps:
Breaking complex tasks into step-by-step plans
Determining the current subtask based on the scene
This multi-modal chain of thought combines both language reasoning and visual localization, using synthetic annotations from other foundation models (like Gemini and SAM) for training.
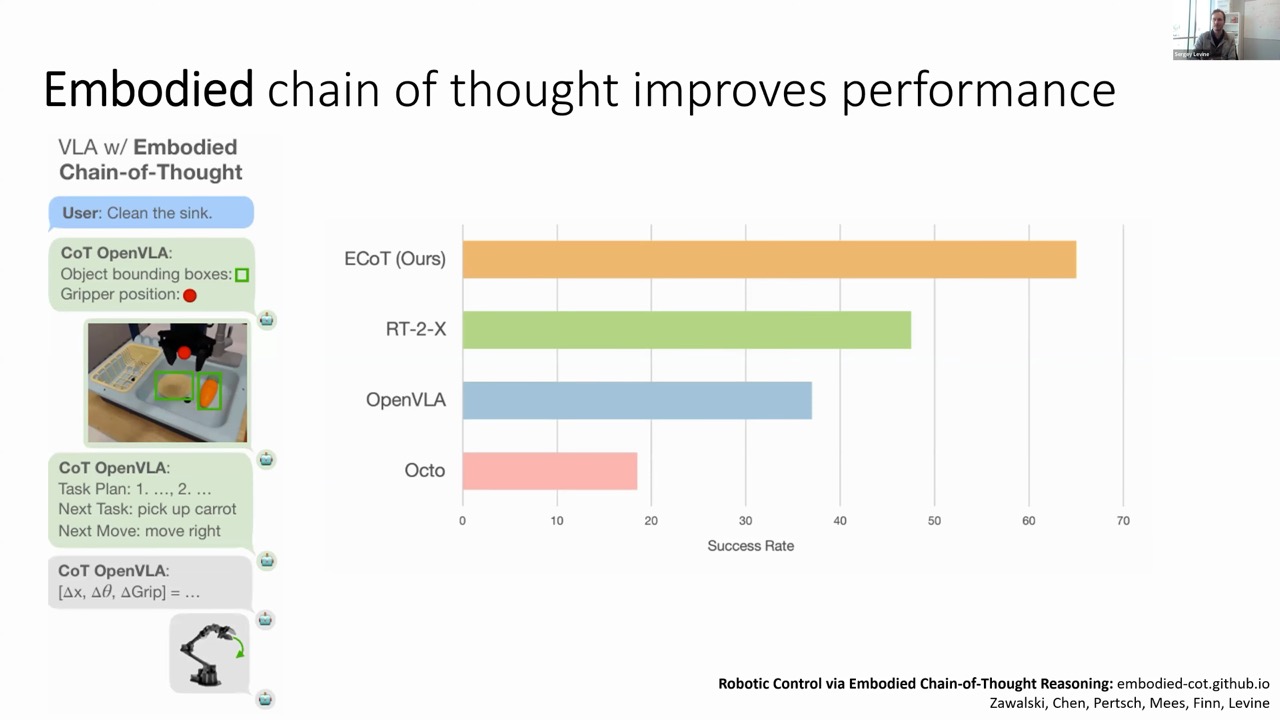
The results were impressive—embodied chain of thought improved performance by approximately 50% compared to standard VLAs, demonstrating that "thinking harder" at test time significantly benefits robotic performance.
This approach also enables corrections. When a robot misinterprets a command (like confusing "not yellow" to mean "pick up the yellow object"), a larger language model can correct the chain of thought, helping the robot execute the correct action.
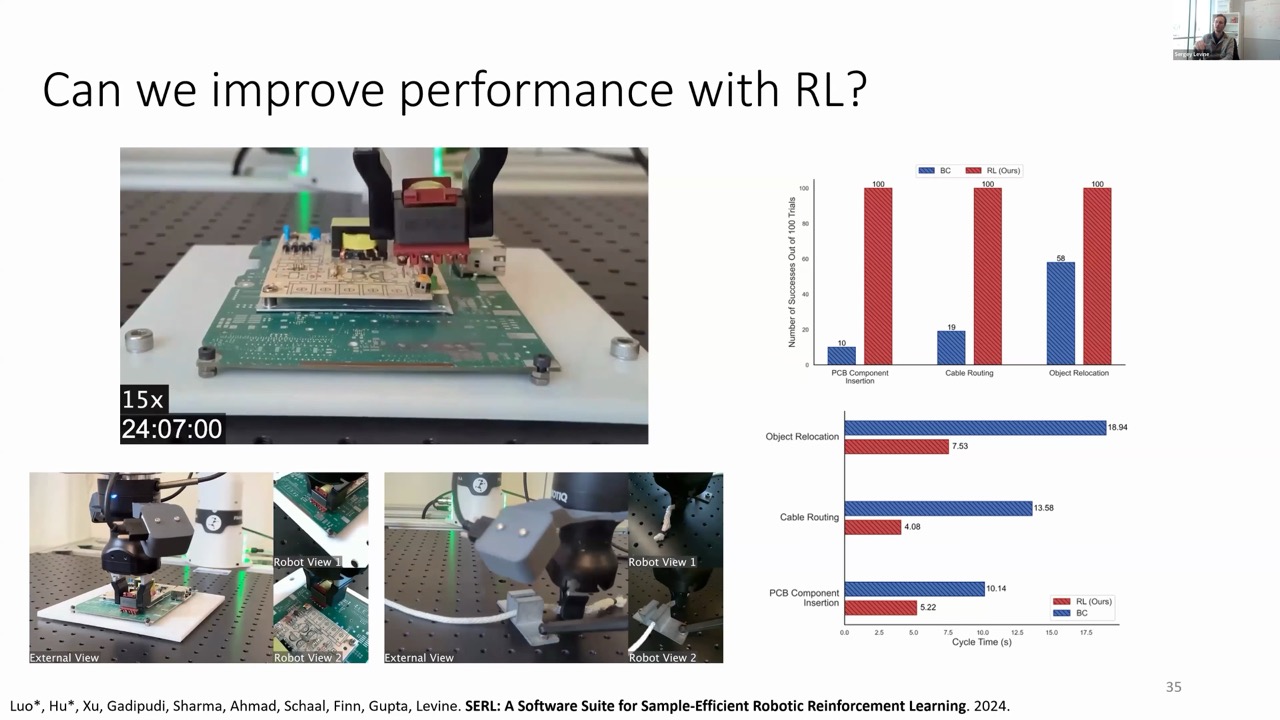
Boosting Performance with Reinforcement Learning
Another frontier in robotic foundation models is incorporating reinforcement learning (RL) to optimize for performance, not just imitation. Recent experiments show RL methods have become extremely efficient for real-world robotics:
A robot learning to insert a chip into a PCB board achieved initial success after just 8 minutes of training
After 30 minutes, it reached 100% success rate
RL-trained policies significantly outperformed imitation learning in both success rate and speed (2-3x faster cycle times)
The researchers used an algorithm called RLPD (Reinforcement Learning with Prior Data), essentially off-policy actor-critic initialized with demonstrations. They incorporated human interventions, where operators could correct the robot when it made mistakes, providing both negative reward signals and higher-quality data.
This approach enabled learning extremely complex tasks like:
Bimanual dashboard assembly with precise pin alignment
Timing belt assembly (handling flexible objects)
IKEA furniture assembly
Dynamic tasks like egg flipping and Jenga piece removal
Computer assembly (inserting RAM, hard drives, and routing cables)
The Future: Merging RL and VLAs for Robust, Generalizable Robots
How might RL feed into vision-language action models? One promising approach is to train smaller specialist policies with RL that master individual domains, then distill their experience into VLAs.
In experiments with connector insertion, researchers:
Trained RL policies for three different connector types
Distilled that experience into a pre-trained VLA model
Tested on new, unseen connectors
The resulting policies combined the generalizable representations from VLAs with the precise, specialized data from RL—creating robots that were both generalizable and precise.
Another exciting direction is self-supervised learning, where robots generate their own goals and fine-tune themselves. In recent work, image-editing diffusion models generate goal images based on VLM-proposed tasks, allowing robots to "play" with their environment and learn autonomously.
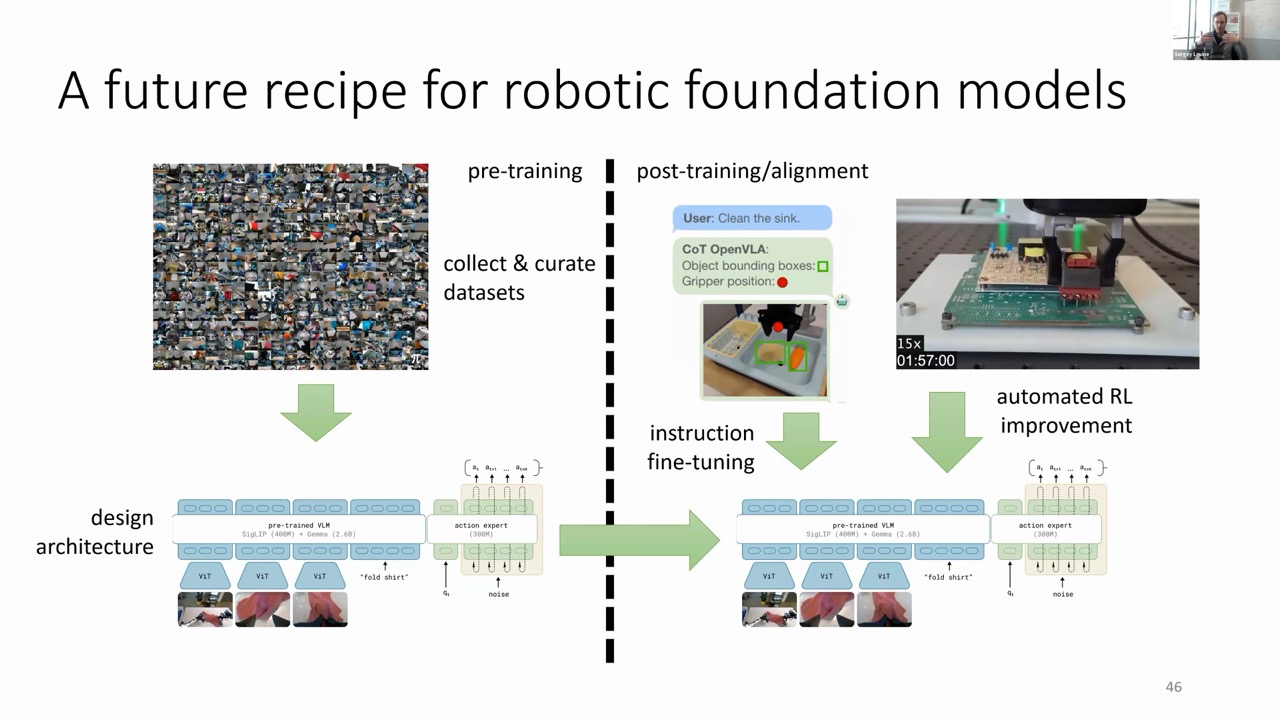
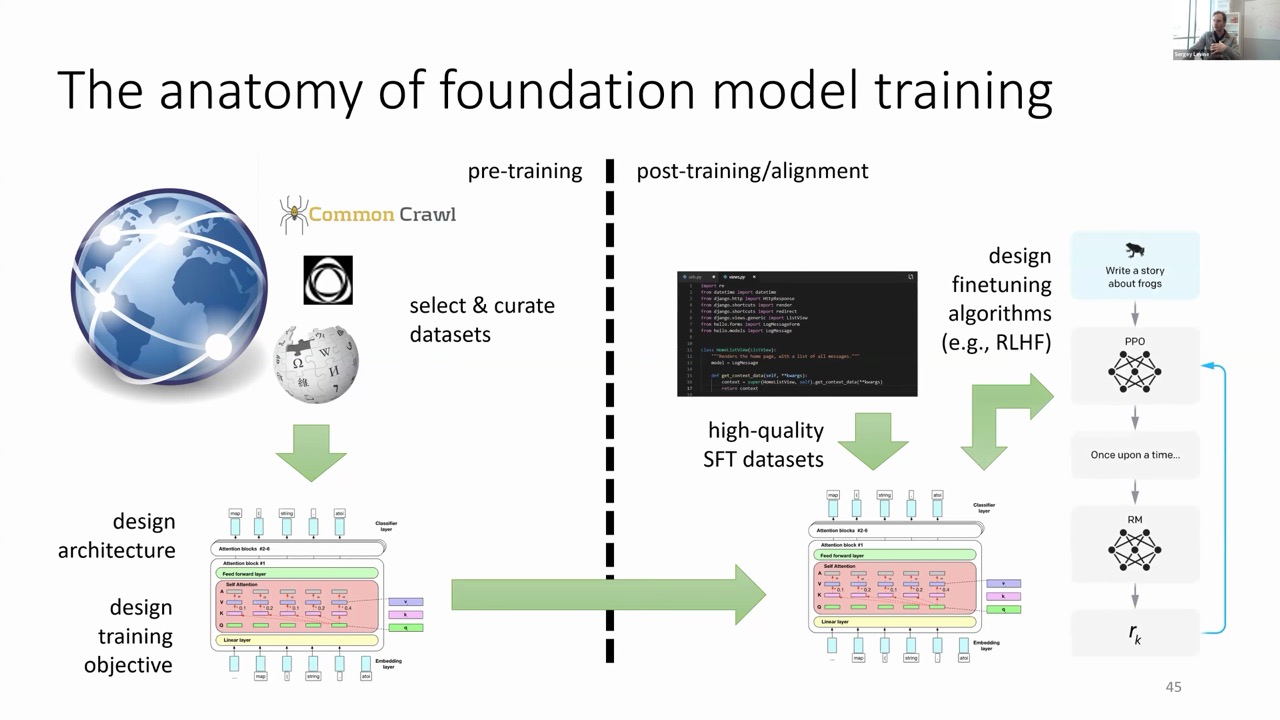
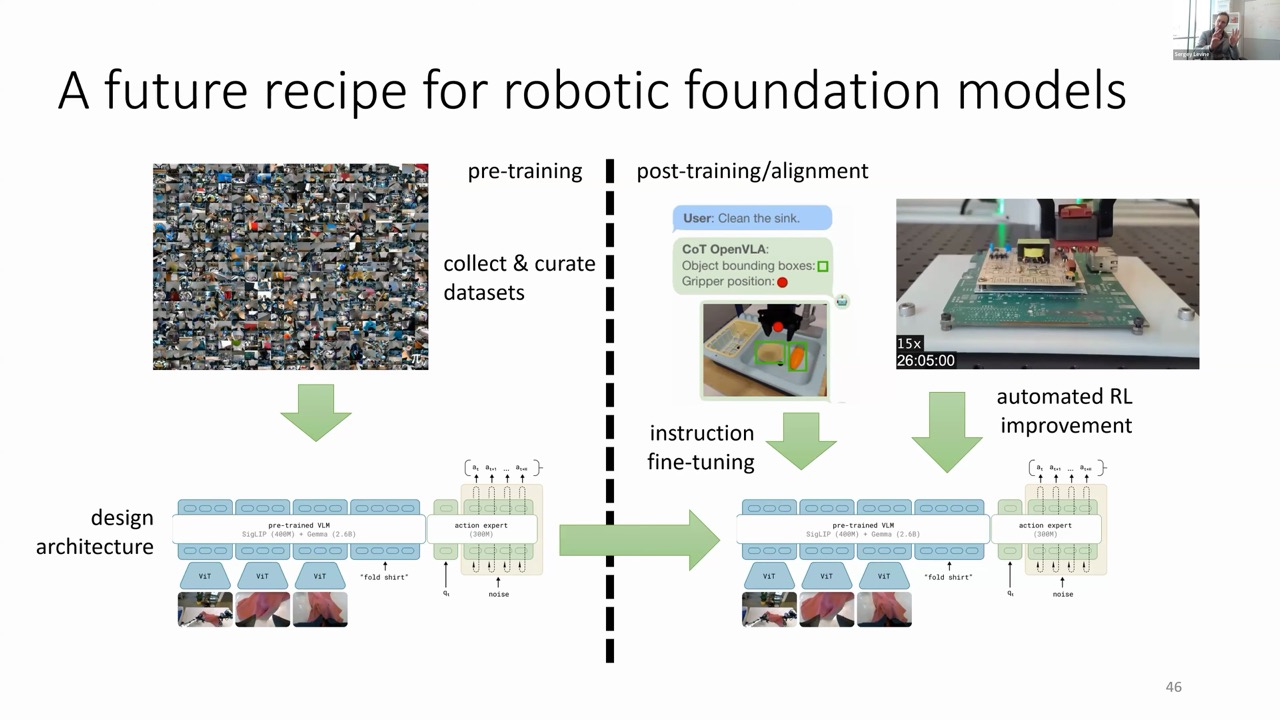
A fascinating parallel is emerging between the successful recipe for language/vision foundation models and robotic foundation models: For language/vision models:
Pre-training on web-scraped data with self-supervised objectives
Post-training/alignment with high-quality supervised data
Fine-tuning with reinforcement learning
For robotic foundation models:
Pre-training on diverse robot data across embodiments
Post-training with high-quality demonstrations
Sequential reasoning through embodied chain of thought
Performance optimization through reinforcement learning
Open Questions and Future Directions
Despite impressive progress, several open questions remain:
Architecture design: How best to incorporate high-level reasoning?
Knowledge transfer: What's the optimal way to transfer knowledge from the web to physical robotic tasks?
Model-based approaches: How might system dynamics models complement or enhance foundation model approaches?
Data economics: Can robots collecting their own useful data change the economics of scaling laws?
As robots become more capable of performing useful real-world tasks, they could collect valuable data while solving practical problems—potentially creating a virtuous cycle of improvement that scales differently than traditional foundation models.
We stand at the beginning of a transformative era for robotics. Foundation models are bridging the gap between the digital world of language and vision and the physical world of manipulation and interaction. Just as foundation models revolutionized NLP and computer vision, robotic foundation models promise to dramatically lower the barriers to creating capable, adaptable robots.
The combination of cross-embodiment training, vision-language-action architectures, sequential reasoning, and reinforcement learning creates a powerful recipe for robots that can understand our world, follow our instructions, and manipulate their environment with increasing skill and precision.