geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
Alibaba Cloud Announced Open Source Qwen2.5-Omni-7B Multimodal AI with End-to-End Capabilities
Updated: March 27 2025 15:01
Alibaba Cloud has unveiled Qwen2.5-Omni-7B, an innovative end-to-end multimodal model to handle diverse inputs—including text, images, audio, and videos—while generating both text and natural speech responses in real-time. This versatility marks a significant evolution from earlier models that typically excelled in only one or two modalities.
For context, many competing multimodal models often require significantly larger parameter counts to achieve similar functionality, making them impractical for deployment on edge devices like smartphones or laptops.
This balance of size and capability establishes Qwen2.5-Omni-7B as an ideal foundation for developers looking to build responsive, cost-effective AI applications that can run efficiently on consumer hardware rather than requiring constant cloud connectivity or specialized hardware.
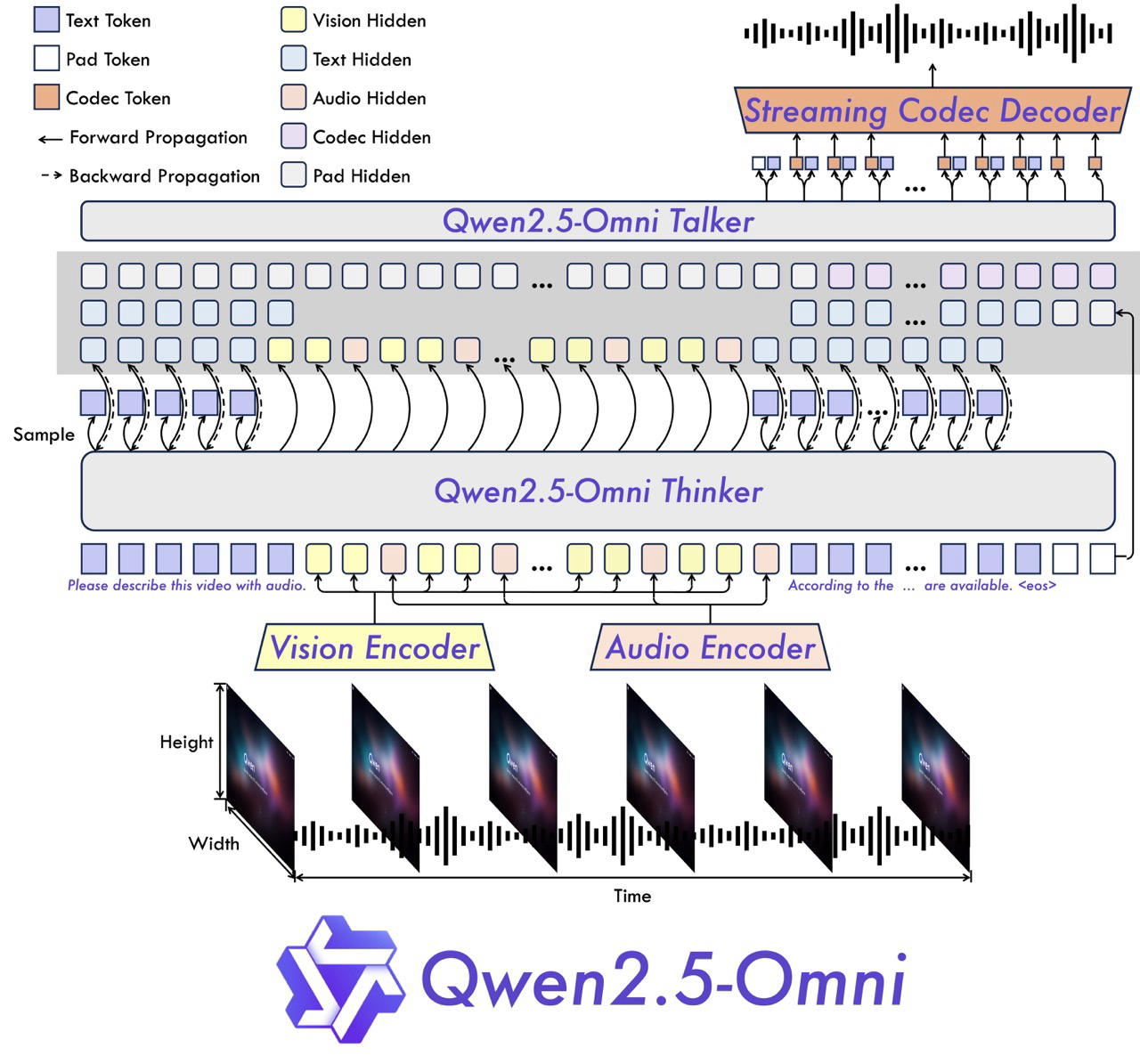
The Qwen2.5-Omni-7B Architecture
The performance of Qwen2.5-Omni-7B stems from several architectural innovations that Alibaba Cloud has incorporated:
Thinker-Talker Architecture: This novel approach separates the model's functions into two distinct components—the "Thinker" handles text generation while the "Talker" manages speech synthesis. By segregating these tasks, the model minimizes interference between different modalities, resulting in higher-quality outputs across the board.
TMRoPE (Time-aligned Multimodal RoPE): This specialized position embedding technique enables better synchronization between video inputs and audio components. By maintaining temporal alignment, the model can generate more coherent content when dealing with time-based media.
Block-wise Streaming Processing: This innovation allows the model to process information in manageable blocks, enabling low-latency audio responses that create more natural and seamless voice interactions. Rather than waiting to process an entire input before responding, the model can begin generating output while still ingesting information.
Together, these architectural features allow Qwen2.5-Omni-7B to deliver performance that rivals specialized single-modality models of comparable size—an achievement that seemed technically unfeasible just a few years ago.
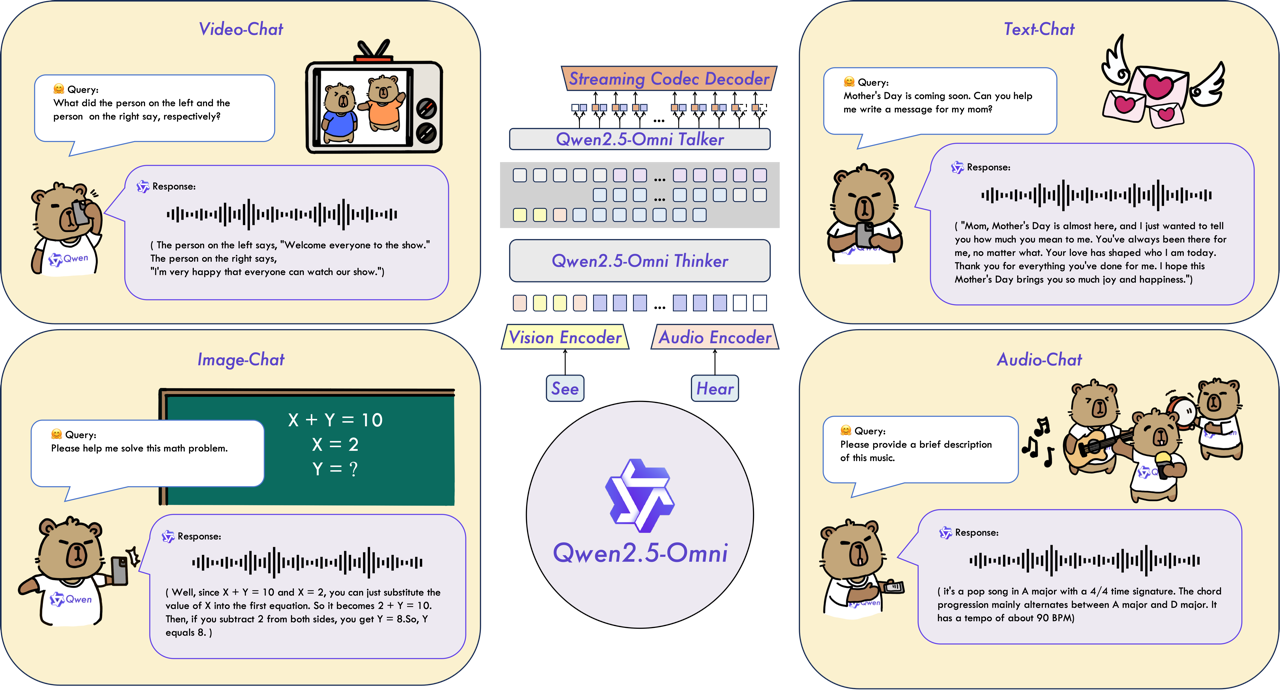
While the technical specifications of Qwen2.5-Omni-7B are impressive, the real impact lies in its potential practical applications:
Accessibility Tools: The model could transform the lives of visually impaired users by providing real-time audio descriptions of their environment. Imagine a smartphone app that can describe objects, read text from signs, and help navigate unfamiliar spaces—all through natural conversation.
Interactive Learning: Cooking enthusiasts could receive step-by-step guidance by simply showing their phone camera the ingredients they have available. The model could analyze the visual input, suggest recipes, and provide verbal instructions as the user cooks.
Enhanced Customer Service: Businesses could deploy chatbots capable of genuinely understanding customer needs through text, voice, or even video demonstrations of product issues, creating more satisfying support experiences.
Language Learning: Students could practice conversations with an AI that not only understands their speech but can see their expressions and gestures, providing more holistic language instruction.
The compact size of the model means these applications could run primarily on the user's device, addressing privacy concerns while ensuring functionality even with limited internet connectivity.
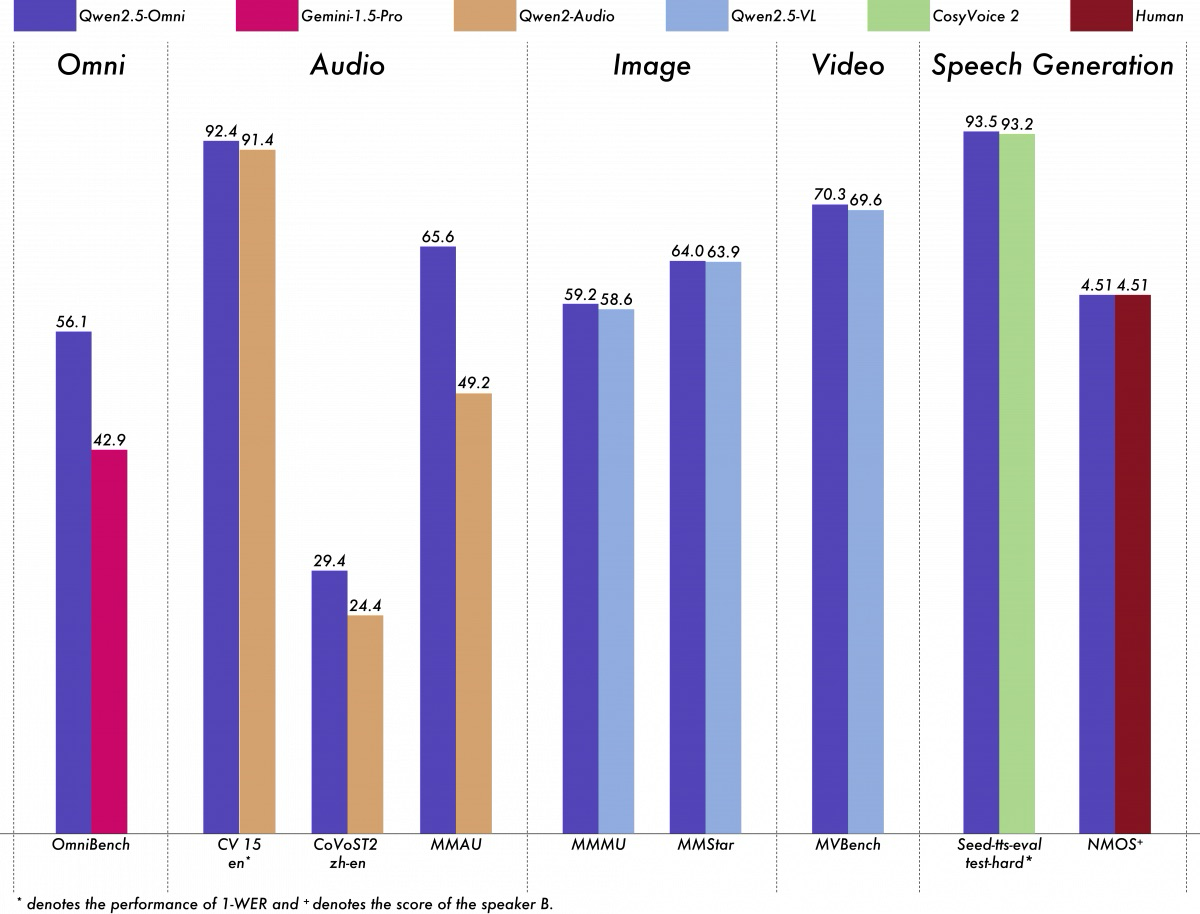
Training and Performance: Setting New Benchmarks
Alibaba Cloud didn't sacrifice performance for size with Qwen2.5-Omni-7B. The model was pre-trained on a diverse dataset encompassing image-text pairs, video-text content, video-audio data, audio-text combinations, and pure text information. This comprehensive training regime ensures robust performance across a wide range of tasks.
Particularly impressive is the model's ability to follow voice commands, achieving performance levels comparable to pure text input—a significant achievement for multimodal systems. When evaluated on OmniBench, a rigorous testing framework designed to assess cross-modal recognition, interpretation, and reasoning, Qwen2.5-Omni-7B achieved state-of-the-art results.
After reinforcement learning optimization, the model showed marked improvements in several key areas:
Reduced attention misalignment
Fewer pronunciation errors
Minimized inappropriate pauses during speech responses
These improvements translate to a more natural and intuitive user experience, addressing common pain points in human-AI interaction.
Qwen2.5-Omni-7B Open Source Availability
In keeping with Alibaba Cloud's commitment to advancing AI research and development, Qwen2.5-Omni-7B has been made available as an open-source resource. Developers and researchers can access the model through Hugging Face, GitHub, Qwen Chat interface, Alibaba Cloud's ModelScope community.
Qwen2.5-Omni-7B joins an expanding ecosystem of specialized models from Alibaba Cloud. Last September, the company unveiled the initial Qwen2.5 release, followed by Qwen2.5-Max in January 2025. The latter has garnered significant recognition, ranking 7th on Chatbot Arena and demonstrating capabilities comparable to top proprietary large language models. The ecosystem also includes:
Qwen2.5-VL: Optimized for enhanced visual understanding
Qwen2.5-1M: Specialized for handling long context inputs
Qwen2.5-Omni-7B represents a significant milestone in the evolution of multimodal AI. By combining comprehensive input processing capabilities with responsive output generation in a deployable package, Alibaba Cloud has created a foundation for more natural, intuitive, and accessible AI applications.