AI Summary: DeepSeek has released its latest large language model, DeepSeek V3-0324, with 685 billion parameters and an MIT license allowing free commercial use. The model features a revolutionary MoE architecture, MLA, and MTP, delivering top-tier performance while reducing computational demands. It demonstrates significant improvements across various benchmarks, including reasoning tasks, front-end web development, Chinese writing proficiency, and interactive capabilities, making it a radical departure from traditional AI models requiring massive data centers.
March 25 2025 08:06On March 24, 2025, DeepSeek quietly uploaded its latest large language model to
Hugging Face — no press release, no marketing blitz, just pure technological innovation. With 685 billion parameters and an MIT license that allows free commercial use, DeepSeek V3 represents more than just another AI model. It's a statement about the future of open source LLM models.
Under the Hood: A New Approach to AI Efficiency
What sets DeepSeek V3 apart isn't just its size, but its revolutionary architecture:
- Mixture-of-Experts (MoE) Architecture: Unlike traditional models that activate all parameters for every task, DeepSeek V3
- selectively activates only about 37 billion of its 685 billion parameters.
- Multi-Head Latent Attention (MLA): Enhances context maintenance across long text passages.
- Multi-Token Prediction (MTP): Generates multiple tokens per step, boosting output speed by nearly 80%.
The result? A model that delivers top-tier performance while dramatically reducing computational demands. DeepSeek's approach stands in stark contrast to the closed models of Western tech giants. While companies like OpenAI and Anthropic keep their models behind paywalls, DeepSeek has chosen a path of radical openness. This strategy is rapidly transforming the global AI ecosystem, creating opportunities for startups, researchers, and developers worldwide.
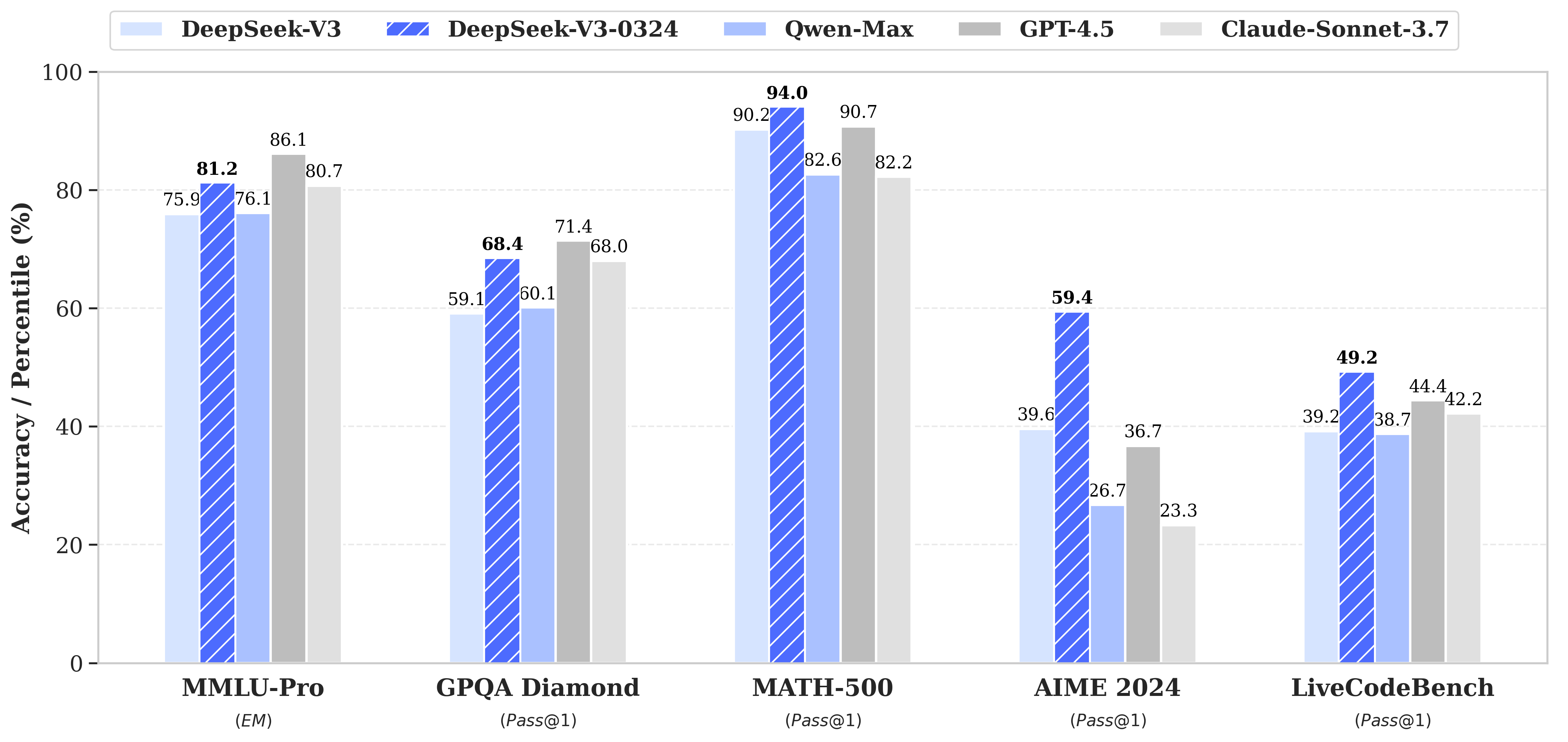
DeepSeek-V3-0324 demonstrates notable improvements over its predecessor, DeepSeek-V3, in several key aspects.
DeekSeek V3 Reasoning and Performance Breakthrough
DeepSeek V3 has demonstrated remarkable improvements across critical benchmarks that showcase its enhanced capabilities. In reasoning tasks, the model has made significant leaps, with the MMLU-Pro benchmark jumping from 75.9 to 81.2, and the AIME benchmark showing a dramatic increase from 39.6 to 59.4.
The model's prowess extends beyond pure reasoning. In front-end web development, DeepSeek V3 has shown improved code executability and a heightened ability to create more aesthetically pleasing web pages and game interfaces. Its Chinese writing proficiency has also seen notable enhancements, with the model now aligning more closely with the R1 writing style and demonstrating superior quality in medium-to-long-form writing.
Perhaps most impressive are the improvements in function calling and interactive capabilities. The model has increased its accuracy in complex interactions, resolving issues from previous versions and providing more nuanced and precise responses.
Running DeekSeek on Mac Studio with the new M3 Ultra
Perhaps most surprising is the model's ability to run on consumer hardware. Researchers have demonstrated DeepSeek V3 running at over 20 tokens per second on a
Mac Studio with an M3 Ultra chip. This is a radical departure from the massive data center setups typically required for state-of-the-art AI models.
What's Next: DeepSeek R2
Industry watchers are already anticipating DeepSeek-R2, a reasoning-focused model expected to launch in April. If it follows the trajectory of its predecessor, it could pose a significant challenge to OpenAI's upcoming GPT-5, demonstrating the power of open-source innovation.
DeepSeek V3 represents more than a technological achievement. It embodies a vision of democratized AI access, challenging the notion that cutting-edge technology should be confined to well-resourced corporations.
Recent Posts