geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
DeekSeek R1 System Requirements Guide on Macbook and Mac Studio M3 Ultra
March 16 2025 16:11
Running machine learning models like DeepSeek on macOS has become increasingly practical with advancements in Apple Silicon's unified memory and processing power. DeepSeek is a powerful tool for various AI applications, but it requires significant resources depending on the model size. DeepSeek R1 distinguishes itself through its innovative training methodology, primarily leveraging large-scale reinforcement learning (RL) with minimal supervised fine-tuning. This approach enabled the model to develop robust reasoning abilities organically.
This guide covers everything you need to know about Mac hardware specifications for DeepSeek, including full and quantized models, memory needs, and recommended machines.
DeepSeek R1: Integrating Supervised Learning for Enhanced Performance
The initial iteration, DeepSeek-R1-Zero, was trained exclusively using Group Relative Policy Optimization (GRPO), a variant of policy gradient methods that eliminates the need for a separate "critic" model by normalizing rewards within a group of generated outputs, reducing computational cost. This method allowed the model to learn from vast amounts of inference data without direct human supervision, resulting in notable reasoning capabilities. However, challenges such as repetition and readability issues were observed in its outputs.
To address these challenges, the development of DeepSeek R1 incorporated initial supervised data before RL training. This integration aimed to improve output readability and coherence while maintaining the robust reasoning skills developed through reinforcement learning. The combination of supervised fine-tuning and reinforcement learning resulted in a model capable of delivering more accurate and user-friendly responses.
The DeepSeek R1 model is no small feat to run efficiently. At 671 billion parameters and weighing in at 404GB, this model typically requires extensive GPU setups with significant VRAM. Traditional PC configurations would need multiple high-end GPUs working in tandem, resulting in extreme power consumption levels. Running large language models (LLMs) like DeepSeek R1 locally on devices such as the new Mac Studio with M3 Ultra offers several significant advantages:
Enhanced Privacy and Data Security: Keeping data on local devices ensures that sensitive information remains secure, reducing the risk of exposure associated with transmitting data to external servers.
Reduced Latency and Improved Performance: Local deployment eliminates the delays inherent in cloud-based processing, leading to faster response times and a more seamless user experience.
Cost Efficiency: Operating LLMs locally can lower expenses by removing the need for ongoing cloud service subscriptions and data transfer fees.
Customization and Control: Users have greater flexibility to tailor models to specific requirements, optimizing performance and compliance with particular regulations.
Offline Accessibility: Local models provide the capability to function without internet connectivity, ensuring continuous operation in environments with limited or unreliable network access.
Understanding DeepSeek's Memory Requirements
DeepSeek models vary widely in size, from smaller variants with a few billion parameters to massive models exceeding 600 billion parameters. The memory requirements for these models are substantial, especially for full-precision (FP16) models. For instance, the DeepSeek-LLM 7B model, with 7 billion parameters, requires approximately 16 GB of unified memory, making it suitable for devices like the MacBook Air with M3 chip and 24 GB RAM. On the other end of the spectrum, the DeepSeek V3 671B model, boasting 671 billion parameters, demands around 1,543 GB of unified memory, necessitating a distributed setup across multiple high-end Mac Studio machines equipped with M2 Ultra chips and 192 GB RAM each.
Quantization offers a solution to reduce these hefty memory requirements. By employing lower precision, such as 4-bit quantization, the memory footprint of DeepSeek models can be significantly decreased. For example, the DeepSeek-LLM 7B model's memory requirement drops to approximately 4 GB when quantized, making it feasible to run on a MacBook Air with an M2 chip and 8 GB RAM. Similarly, the DeepSeek V3 671B model's memory needs are reduced to around 386 GB with 4-bit quantization, allowing it to run on a setup of three Mac Studio machines with M2 Ultra chips and 192 GB RAM each.
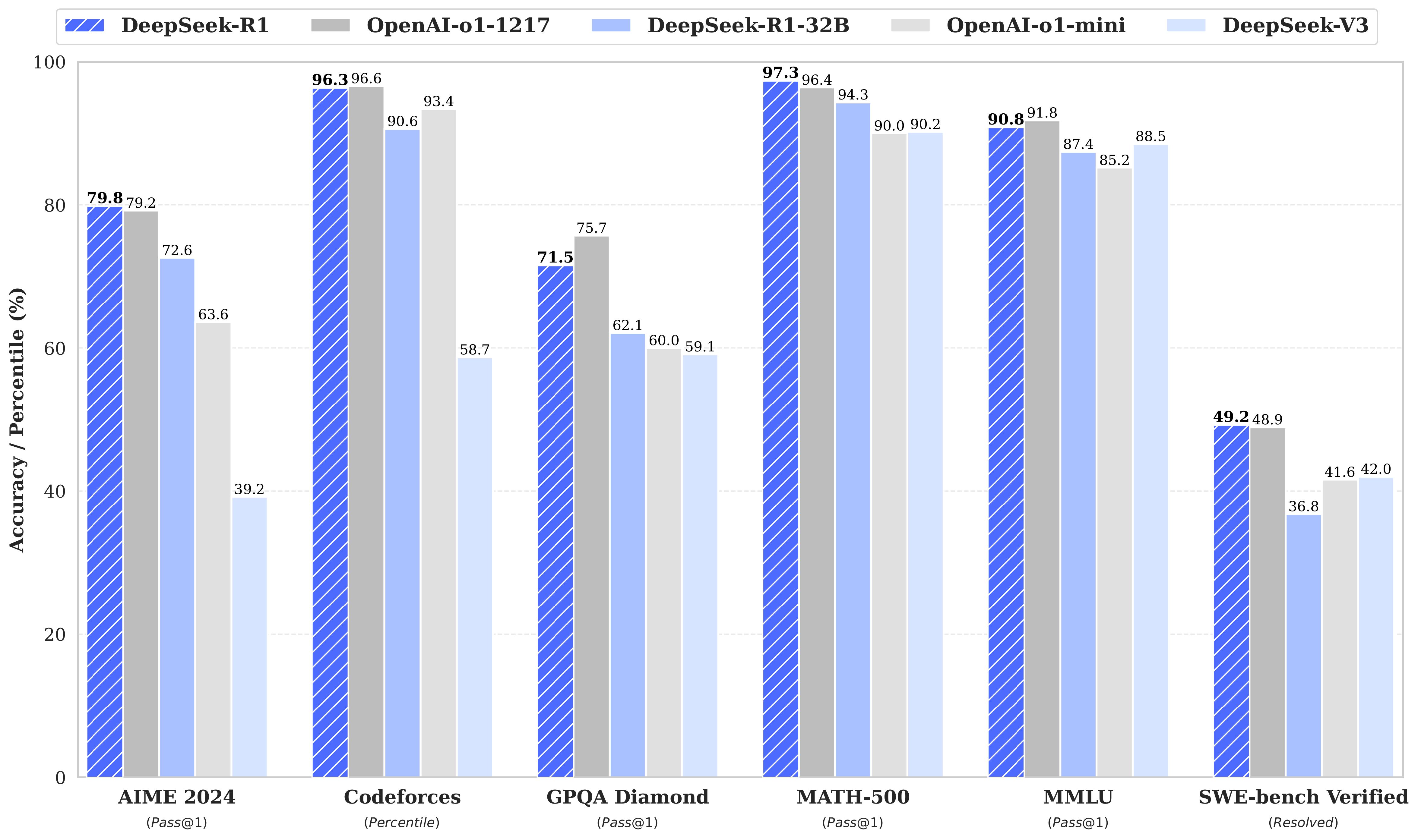
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. Here is the performance comparison:
Recommendations for Apple Silicon Machines
Selecting the appropriate Apple Silicon device depends on the size of your DeepSeek models and their memory requirements. Here's a breakdown of recommendations:
M2/M3/M4 MacBook Air (16GB–24GB): Ideal for small quantized models with fewer than 7 billion parameters such as the deepseek-r1:1.5b or deepseek-r1:7b models.
M2/M3/M4 MacBook Pro or Mac Mini M4 (32GB-64GB): Suitable for mid-range models and some smaller full-precision models such as the deepseek-r1:8b or deepseek-r1:14b models.
M2 Max/Ultra or M4 Max/M3 Ultra Mac Studio (192GB+): Best suited for large full-precision models such as the deepseek-r1:32b or deepseek-r1:70b models.
Mac Pro and distributed setup (Future Consideration): Potentially a key option for extremely large models requiring higher compute & memory.
It's important to note that these recommendations are based on the bare minimum requirements for running the models, assuming no other applications are running on the Mac. For optimal performance and larger context lengths, it's advisable to have more than the minimum required memory. If your available memory barely fits the model, you may need to adjust parameters such as batch size to ensure smooth operation.
Here is the performance of running various DeepSeek models on Mac Mini M4 64G ram with 14/20 Cores/GPUs:
Apple's recent release of the updated Mac Studio, featuring the M4 Max and M3 Ultra chips, marks a significant advancement in desktop computing. These new configurations offer substantial improvements in processing power, memory capacity, and connectivity, catering to professionals with demanding computational needs. The Mac Studio now comes equipped with two powerful chip options:
M4 Max: This chip features a 16-core CPU and up to a 40-core GPU, starting with 36GB of unified memory, expandable up to 128GB.
M3 Ultra: Boasting a 32-core CPU and up to an 80-core GPU, the M3 Ultra supports up to 512GB of unified memory, providing exceptional performance for intensive tasks.
Both configurations include Thunderbolt 5 ports, enhancing data transfer speeds and peripheral connectivity.
Here is the Mac Studio benchmark performance comparison from Carolina Milanesi's in-depth review using a Mac Studio with M3 Ultra SoC, 32-core CPU, 80-core GPU, 256GB Unified Memory (192GB usable for VRAM), and 4TB SSD, compared with an Intel i9 13900K, RTX 5090, 64GB of DDR5, and a 2TB NVMe SSD.
M3 Ultra: Built for AI Excellence
The M3 Ultra chip is designed with a comprehensive suite of features tailored for AI workloads:
32-Core CPU: This high-performance CPU is optimized for heavily threaded tasks, ensuring rapid data processing and analysis.
Up to 80-Core GPU: The powerful GPU delivers exceptional graphics rendering capabilities, supporting complex computations essential for AI model training and inference.
Enhanced Neural Engine: With double the Neural Engine cores compared to previous models, the M3 Ultra accelerates machine learning computations, enabling faster execution of AI algorithms.
UltraFusion Architecture: This innovative design links two M3 Max dies over 10,000 high-speed connections, allowing the chip to operate as a single cohesive unit. This architecture ensures high performance while maintaining energy efficiency.
Over 800GB/s Memory Bandwidth: The substantial memory bandwidth facilitates swift data access and transfer, crucial for handling large datasets and complex models inherent in AI tasks.
M3 Ultra Memory Bandwidth and Cost Considerations
Apple's M3 Ultra chip has managed to run massive model with remarkable efficiency. The key to this performance lies in Apple's unified memory architecture, which provides a shared pool of high-bandwidth memory that functions similarly to dedicated VRAM but with greater flexibility and efficiency. This capability allows for on-device processing, reducing reliance on cloud-based solutions and enhancing data privacy and security. The integration of high-performance CPU and GPU cores, coupled with an advanced Neural Engine, ensures that the Mac Studio can handle the computational demands of extensive AI models efficiently.
The 512GB of unified memory in the M3 Ultra model addresses the growing demands for high-bandwidth memory in professional applications. Achieving such bandwidth with traditional DDR5 setups poses challenges, often requiring multiple CPU complexes to surpass 500GB/s. For instance, AMD's EPYC 9355P processor, priced at $2,998, offers 106GB/s per CCD, necessitating five CCDs to exceed 500GB/s, which increases complexity and cost. The 512GB configuration of the Mac Studio is priced at $9,500 in the United States and €11,000 in Europe, with educational discounts reducing the U.S. price to approximately $8,600.
The enhanced memory and processing capabilities of the new Mac Studio make it particularly appealing for AI and machine learning tasks. The 512GB unified memory allows for efficient hosting of such models, offering a viable alternative to setups like multiple RTX 3090 GPUs. However, it's important to note that while the Mac Studio provides substantial memory bandwidth, the cost of server-grade RAM and the overall system investment remain significant considerations for potential users.
M3 Ultra Technical Specifications and Configuration running DeepSeek R1 model
YouTube channel Dave2D demonstrated that running the DeepSeek R1 model required:
Apple's highest configuration of the M3 Ultra chip
A whopping 512GB of unified memory
Manual adjustment of macOS's default VRAM allocation limits through Terminal commands
Increasing the memory allocation to 448GB
Despite these intensive requirements, the system performed admirably, running the 4-bit quantized version of the model smoothly while maintaining the full 671 billion parameters.
For comparison, here is the performance of running various DeepSeek R1 models on 4090 GPU:
According to Carolina Milanesi's in-depth review at Creative Strategies, the M3 Ultra's performance extends beyond just theoretical benchmarks. The Mac Studio with M3 Ultra was put through rigorous real-world testing with various AI workflows, including multiple LLM models and diffusion models.
The Mac Studio with M3 Ultra consistently outperformed competing systems in these tests, with particular advantages in memory bandwidth and overall system efficiency. Milanesi noted that the system's ability to run continuous AI workloads without thermal throttling was especially impressive, maintaining consistent performance even under extended loads.
Apple's MLX Machine Learning Framework and Optimization
A critical factor in the M3 Ultra's impressive AI performance is Apple's MLX framework. MLX is an open-source machine learning framework designed specifically for Apple silicon, released by Apple in December 2023. Unlike general-purpose frameworks adapted for Apple hardware, MLX was built from the ground up to leverage the unique architecture of Apple's chips, particularly the unified memory design of the M-series processors.
MLX provides a PyTorch-like API that's familiar to machine learning developers while offering optimizations specific to Apple silicon. It supports key ML operations, distributed training across multiple devices, and supports various model architectures including CNNs, Transformers, and diffusion models.
Testing on the M3 Ultra demonstrates MLX's significant performance advantages. When running popular LLM models like Llama 2 and Mistral, MLX showed 2-3x faster inference speeds compared to other frameworks running on the same hardware. This performance boost is particularly noticeable when working with the larger DeepSeek R1 model, where the memory management optimizations in MLX allow for more efficient utilization of the unified memory architecture.
Benchmarks showed MLX achieving token generation speeds up to 20 tokens per second with the DeepSeek R1 model on the M3 Ultra - remarkable performance considering the model's massive 671 billion parameters. For comparison, similar performance would typically require multiple high-end GPUs with traditional frameworks.
One of MLX's key innovations is its approach to array compilation and memory management. Unlike traditional frameworks that often require data movement between CPU and GPU memory spaces, MLX takes full advantage of the unified memory architecture in Apple silicon. The framework uses a just-in-time compilation strategy that optimizes operations for the specific chip configuration it's running on.
On the M3 Ultra, this means operations can be dynamically allocated across CPU cores, GPU cores, and the Neural Engine based on which would provide optimal performance for that specific workload. This dynamic allocation significantly reduces memory bottlenecks and allows for more efficient parallel processing of large models.
Another standout feature noted in the Creative Strategies review was the Mac Studio's thermal and acoustic performance. While running intensive AI workloads that would cause most workstations to sound like a jet engine, the Mac Studio maintained remarkably quiet operation.
Thermal imaging tests showed that the M3 Ultra efficiently distributed heat, avoiding the hot spots that typically lead to throttling in high-performance computing scenarios. This thermal efficiency contributes to the system's ability to maintain consistent performance during extended AI training sessions.
M3 Ultra Unprecedented Power Efficiency
Perhaps the most impressive aspect of this achievement is the power efficiency. While running the DeepSeek R1 model, the entire Mac Studio system drew less than 200W of power. According to Dave2D, comparable performance on traditional PC setups with multiple GPUs would require approximately 10 times more power consumption.
This dramatic difference in energy efficiency highlights one of the significant advantages of Apple's custom silicon approach and unified memory architecture. By integrating the CPU, GPU, and memory into a single chip design, Apple has eliminated many of the bottlenecks and inefficiencies that plague traditional computer architectures.
Interestingly, the tests revealed some unexpected results. The massive 671 billion parameter R1 model actually performed better than its smaller 70-billion-parameter counterpart. This counterintuitive outcome might be attributed to architectural efficiencies in how the unified memory handles larger models, though more research would be needed to fully understand this phenomenon.
Mac Studio Pricing and Configuration Options
The Mac Studio's pricing varies based on configuration: (both models are available for preorder with shipments commencing on March 12)
M4 Max Model: Starts at $1,999 with 36GB of RAM and 512GB of storage.
M3 Ultra Model: Begins at $3,999 with 96GB of RAM and 1TB of storage.
M3 Ultra Model: 28-core CPU, 60-core GPU is $5,599 with 256GB of RAM and 1TB of storage.
M3 Ultra Model: 32-core CPU, 80-core GPU is $9,499 with the highest 512GB of RAM and 1TB of storage.
Running DeepSeek models on macOS is feasible with proper hardware planning. Smaller models can run efficiently on MacBook Air or MacBook Pro devices, but larger models require powerful configurations like the updated Mac Studio with M4 Max and M3 Ultra chips offers professionals enhanced performance and memory capabilities, making it a strong contender for high-demand computing tasks. Prospective buyers should weigh the benefits against the associated costs to determine the best configuration for their specific needs. Unless you need to run the largest DeekSeek R1 671B model, the 28-core CPU, 60-core GPU with 256GB of RAM at $5,599 may be a much better price effective option compared with the 32-core CPU, 80-core GPU with 512GB RAM, the tok/s is only 5% difference between the two machines at 70% price difference.
The Creative Strategies review emphasizes that the Mac Studio with M3 Ultra isn't just impressive in benchmarks but delivers meaningful advantages in real-world AI development scenarios. This development carries significant implications for AI researchers, developers, and enthusiasts. Traditionally, running models of this size required expensive, power-hungry setups with multiple GPUs, limiting accessibility to organizations with substantial computing resources. The M3 Ultra's ability to run such models efficiently democratizes access to advanced AI capabilities.
While Apple has faced criticism for falling behind in the AI race, particularly regarding consumer-facing AI features, this demonstration suggests the company has been making significant progress on the hardware front. With the continued development of MLX and its tight integration with Apple silicon, the Mac Studio with M3 Ultra represents not just a powerful workstation but a glimpse into a future where complex AI models can be developed, trained, and deployed on energy-efficient hardware accessible to a much wider range of researchers and developers.