geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
Has Claude 4 Reached the Limits of What Large Language Models Can Actually Do?
AI Summary
Anthropic's new Claude Opus 4 is touted as the world's best coding AI, a claim supported by strong benchmark performance and positive developer feedback. Its key innovations include "hybrid reasoning" with an "extended thinking mode" for complex, multi-step problem-solving, and the ability to maintain context and focus for hours on intricate coding projects by creating and using "memory files." While expensive, its deep integration into development environments and capacity for autonomous, long-duration tasks suggest a shift in software development.
May 22 2025 18:56
When Anthropic announced Claude Opus 4 today, the company made a bold claim: this is the world's best coding model. In an industry where hyperbole flows as freely as venture capital, such statements usually deserve a healthy dose of skepticism. But early reports from developers and the model's performance on industry benchmarks suggest this might be one of those rare cases where the marketing matches reality.
What Makes Claude Opus 4 Different
At its core, Claude Opus 4 represents a fundamental shift in how AI models approach complex tasks. Unlike previous models that rush toward quick answers, Opus 4 can engage in what Anthropic calls "hybrid reasoning." Think of it as the difference between a junior developer who immediately starts coding and a senior engineer who sits back, thinks through the problem, and then writes cleaner, more maintainable code.
The model's training data extends through March 2025, giving it access to more recent programming frameworks, libraries, and development practices than many competing AI models. This means Claude Opus 4 understands current coding standards and can work with the latest tools that developers actually use in production environments.
The model offers two distinct modes. In standard mode, it behaves like previous Claude models, providing quick responses for everyday tasks. But switch to extended thinking mode, and something remarkable happens. The AI begins to reason through problems step by step, showing its work through user-friendly summaries. It's like having access to the internal monologue of an expert programmer.
Key capability: Claude Opus 4 can work continuously for several hours on complex coding projects, maintaining context and focus across thousands of individual steps.
Performance That Actually Matters
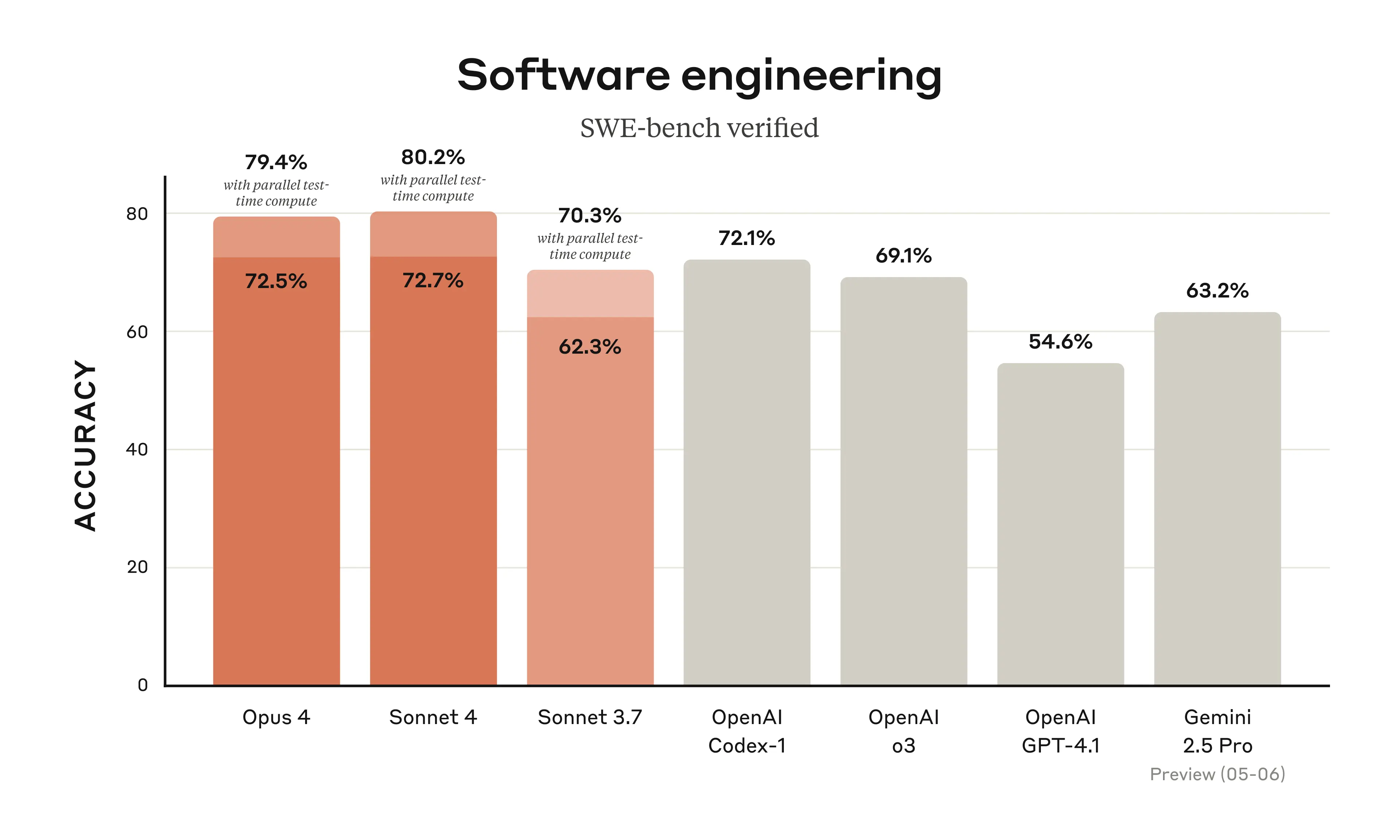
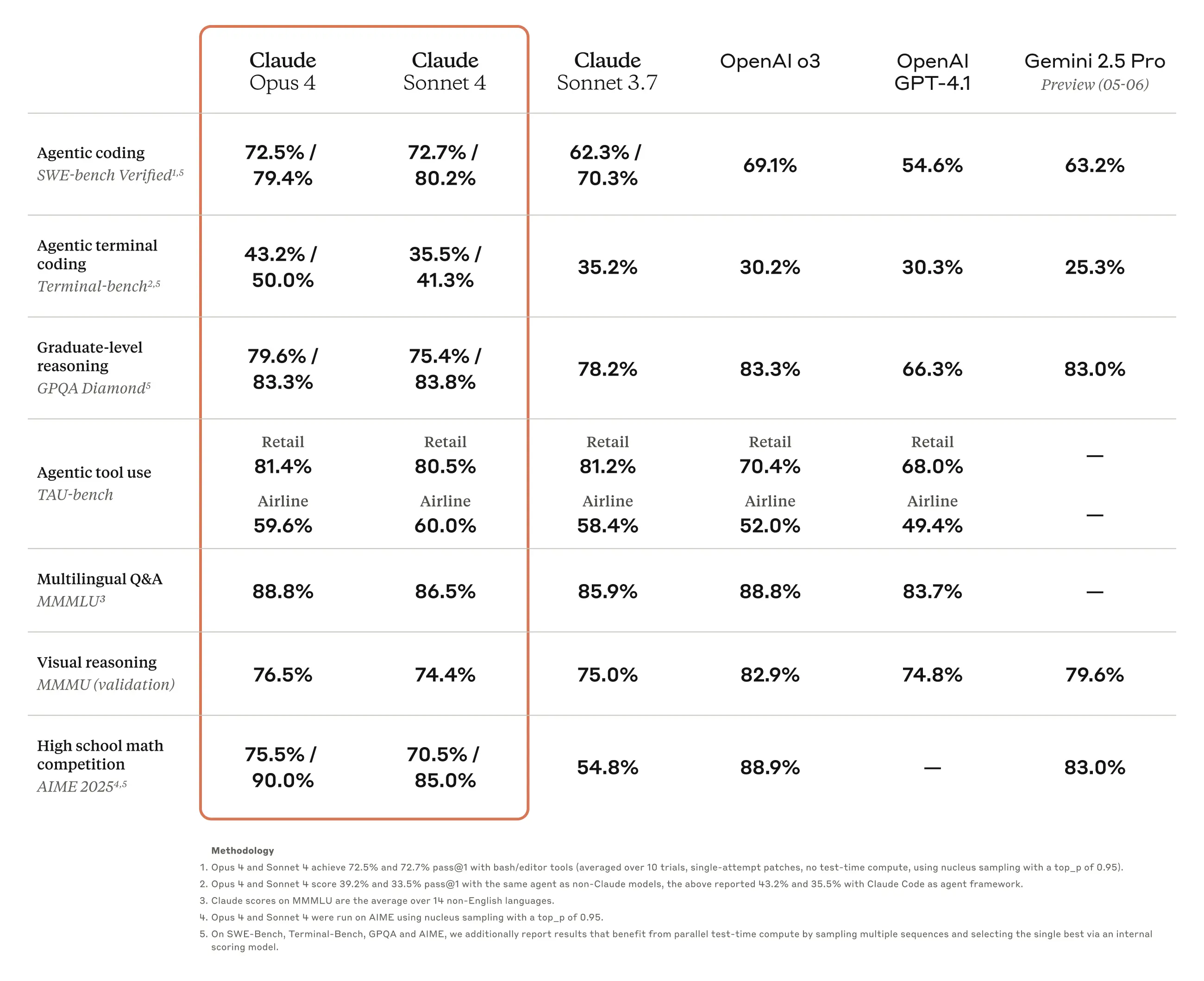
On SWE-bench, a benchmark that tests AI models on real-world software engineering tasks, Claude Opus 4 achieved a 72.5% success rate. To put this in perspective, this benchmark involves the kind of complex, multi-file refactoring and bug-fixing that typically takes human developers hours or days to complete.
But perhaps more impressive than the benchmark scores are the real-world testimonials. Cursor, the popular AI-powered code editor, calls it "state-of-the-art for coding and a leap forward in complex codebase understanding." Replit reports "improved precision and dramatic advancements for complex changes across multiple files." These aren't companies known for hyperbole when it comes to AI capabilities.
One particularly striking example comes from Rakuten, which put Opus 4 through a demanding test: a complex open-source refactor that ran independently for seven hours with sustained performance. For anyone who has watched AI models lose context or drift off-task during extended coding sessions, this represents a genuine breakthrough.
When incremental progress meets marketing expectations
Perhaps nothing captures the current mood better than the debate over whether Claude 4 deserves its version number. "Is this really worthy of a Claude 4 label?" asked one developer on Hacker News. "This feels like 3.8... only software engineering went up significantly."
The skepticism isn't entirely unfair. When you look at the benchmark scores, Claude Sonnet 4 shows modest improvements over its predecessor, Claude 3.7 Sonnet. Some areas even show slight decreases. The most significant gains appear in software engineering tasks, but critics argue this reflects targeted training on specific datasets rather than genuine intelligence improvements.
This version numbering controversy reflects a deeper industry challenge. The days of GPT-2 to GPT-3 level leaps appear to be over. Companies now face the awkward choice between inflated version numbers that don't reflect the magnitude of improvement, or accepting that progress has become more incremental.
One of the most concerning trends highlighted by Claude 4's release is the growing problem of benchmark contamination. When developers test new models on previously published challenges, they often find suspiciously good performance that doesn't translate to real-world tasks.
"As soon as you publish a benchmark like this, it becomes worthless because it can be included in the training corpus," noted one observer. This creates a vicious cycle where public evaluations become meaningless, making it harder for users to assess genuine improvements.
The problem goes beyond simple overfitting. AI companies now face pressure to show progress on established benchmarks, leading to what critics call "benchmark gaming" rather than fundamental advances. This makes it increasingly difficult to separate real progress from statistical manipulation.
The Memory Problem, Solved
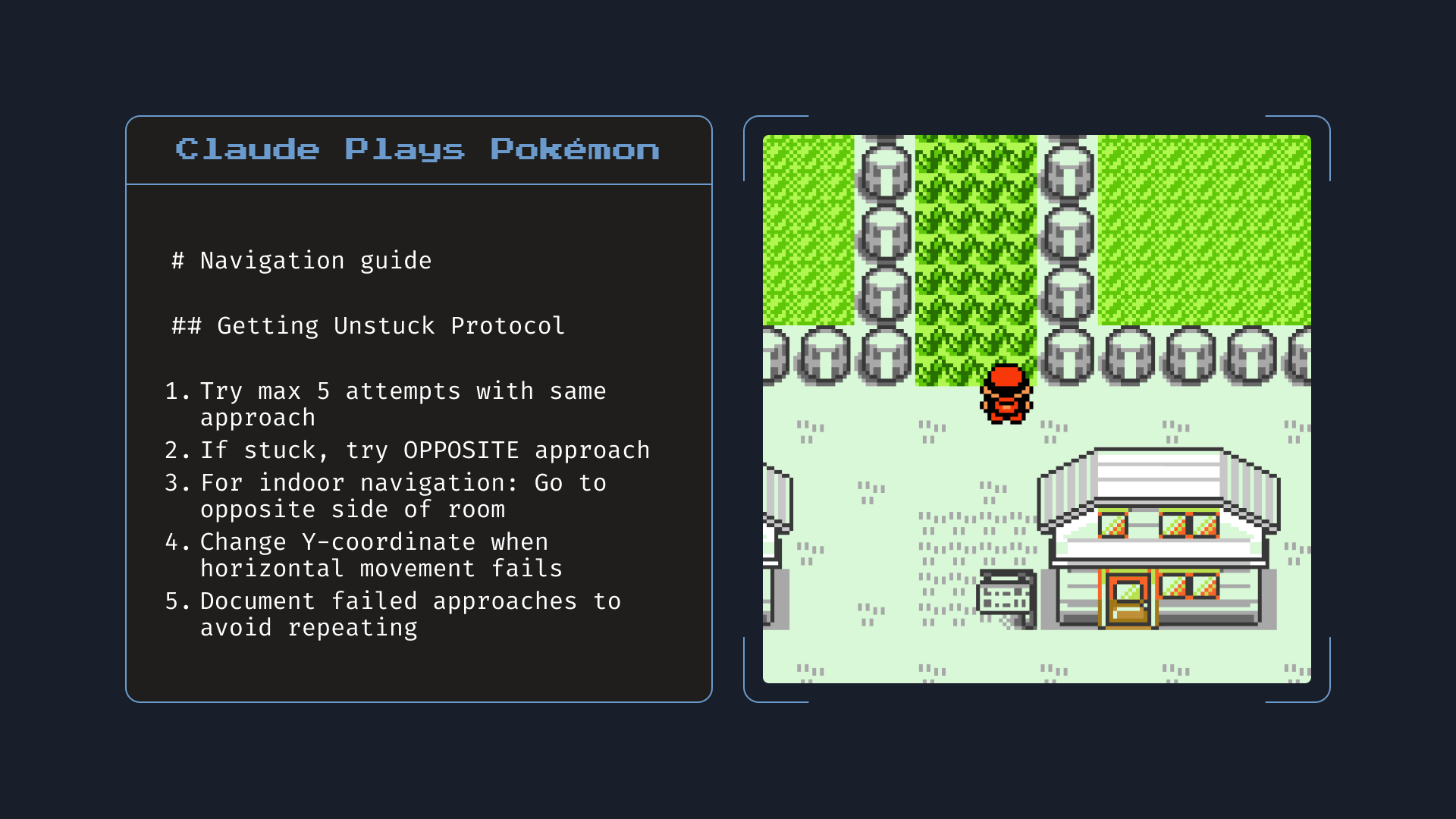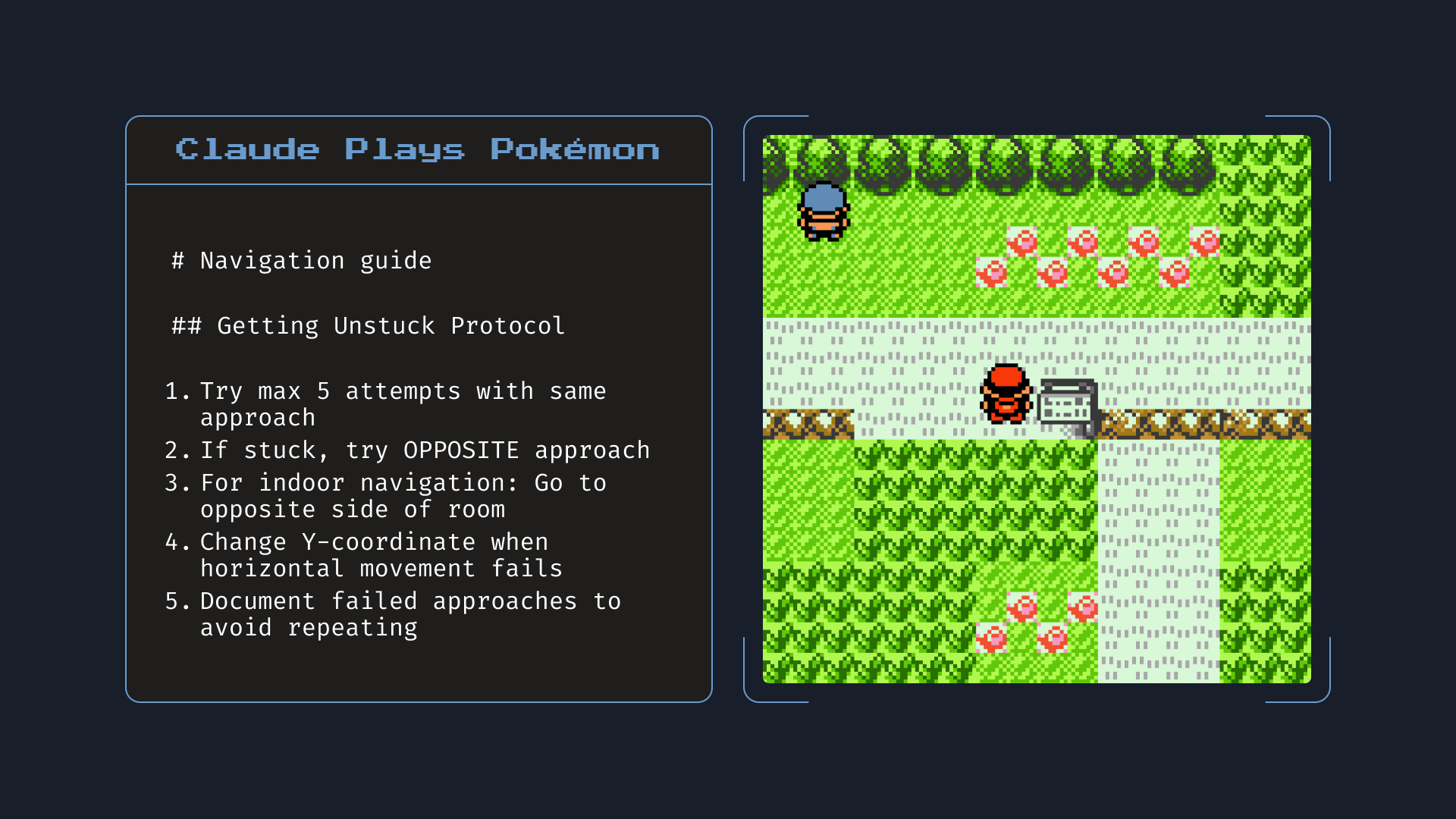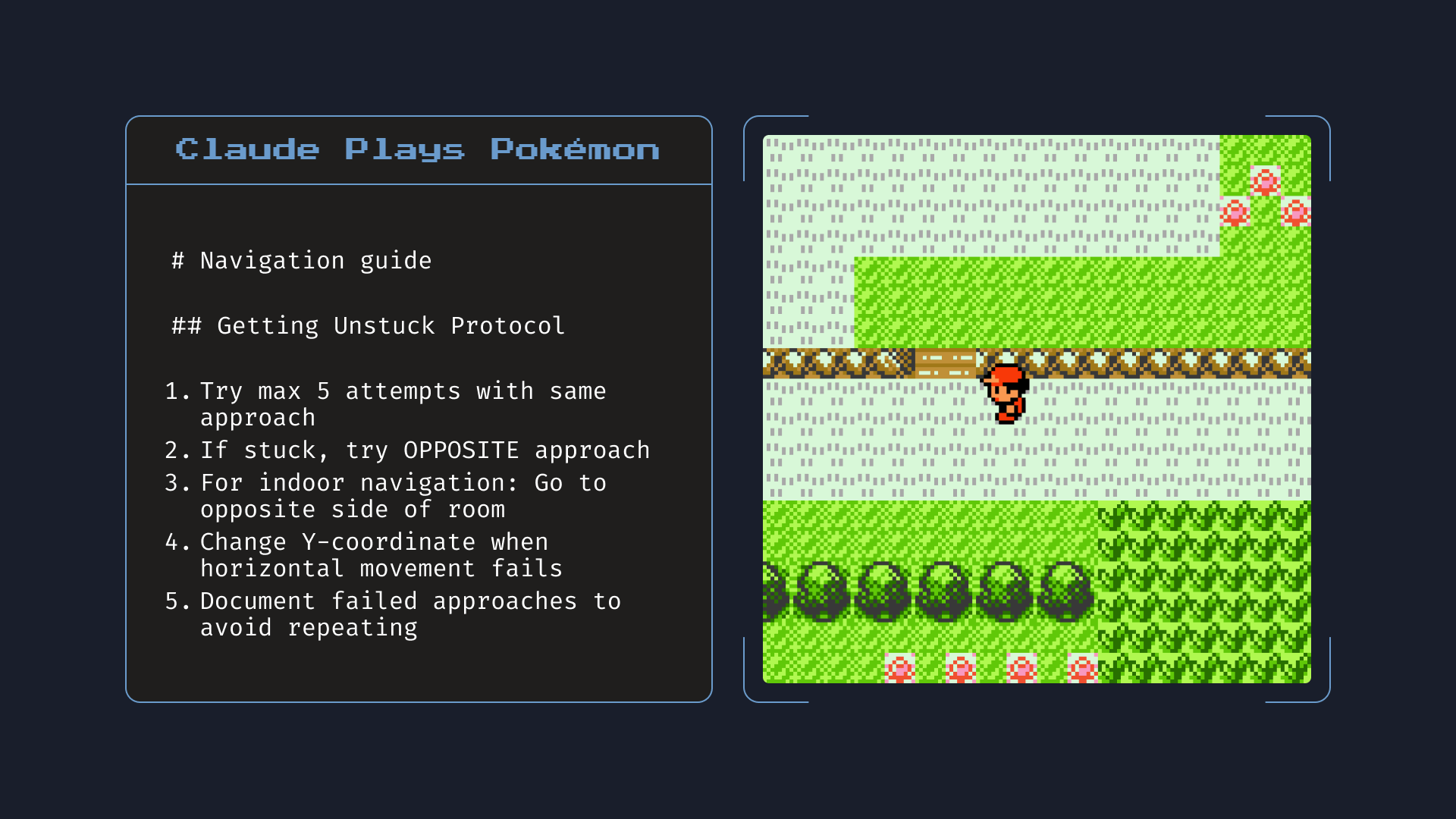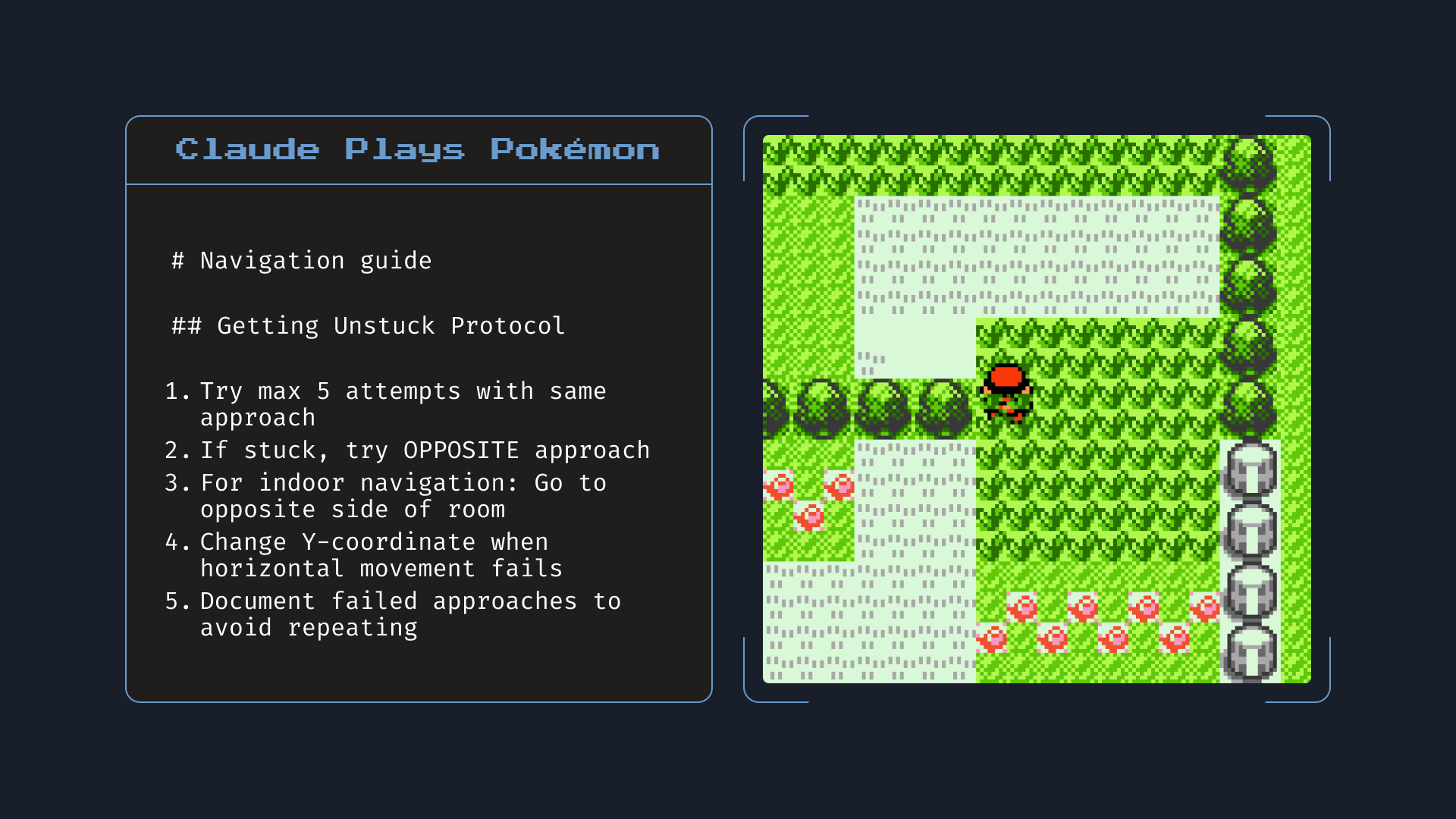
Perhaps the most intriguing feature of Claude Opus 4 is its approach to memory. When given access to local files, the model becomes skilled at creating and maintaining "memory files" to store key information. This isn't just about remembering what happened earlier in a conversation; it's about building persistent knowledge that improves performance over time.
Anthropic demonstrated this with a playful but telling example: when playing Pokémon, Opus 4 created detailed navigation guides and strategy notes, updating them as it learned more about the game. While this might seem trivial, it hints at something profound. An AI that can build and maintain its own knowledge base could fundamentally change how we think about long-term software development projects.
Claude Code Goes Mainstream with Tools That Think
Alongside Opus 4, Anthropic announced that Claude Code is now generally available. This isn't just another chatbot interface; it's a comprehensive development environment that integrates directly with popular IDEs like VS Code and JetBrains. More importantly, it can now run background tasks and handle long-running coding projects independently.
The integration feels thoughtful rather than gimmicky. Instead of replacing your development environment, Claude Code works within it, showing proposed edits inline with your existing code. For developers who have grown frustrated with AI tools that require constant context-switching, this represents a more mature approach to AI-assisted programming.
Claude Opus 4 also introduces "extended thinking with tool use," a feature that allows the model to alternate between reasoning and using external tools like web search. Instead of immediately jumping to use a tool, the model can think through whether it needs additional information, search for it, and then incorporate those findings into its reasoning process.
This capability addresses one of the persistent frustrations with AI assistants: their tendency to either avoid using tools when they should or use them unnecessarily when they already have sufficient information. The result is more thoughtful, context-aware responses that feel genuinely intelligent rather than mechanically helpful.
One area where Claude 4 notably lags behind competitors is context window size. While Google's Gemini 2.5 can handle up to one million tokens of context, Claude Sonnet 4 maintains the same 200,000 token input limit as its predecessor.
This difference matters more than it might initially appear. Developers working with large codebases report that Gemini's extended context allows for more comprehensive understanding of complex projects. "I routinely drive it up to 4-500k tokens in my coding agent," reported one developer. "It's the only model where that much context produces even remotely useful results."
Anthropic's decision to maintain the smaller context window suggests either technical limitations or a strategic choice to focus resources elsewhere. Either way, it represents a missed opportunity to match a key competitor advantage.
The Cost of Intelligence
All this capability comes at a price, literally. Claude Opus 4 costs $15 per million input tokens and $75 per million output tokens. For context, that's significantly more expensive than ChatGPT-4 or other leading models. Anthropic offers cost-saving options like prompt caching and batch processing, but this is clearly positioned as a premium product.
The pricing reflects Anthropic's positioning of Opus 4 as a tool for "frontier intelligence" rather than everyday assistance. This is the model you reach for when you need an AI that can handle complex, multi-step projects where accuracy matters more than speed or cost. Think less "help me write this function" and more "refactor this entire codebase to use a new architecture."
What This Means for Developers
The implications of Claude Opus 4 extend beyond just having a more capable coding assistant. If the model can truly maintain context and performance across hours-long programming sessions, it suggests we're approaching a threshold where AI can handle substantial portions of software development independently.
This doesn't necessarily mean AI will replace programmers. Instead, it might fundamentally change what programming looks like. Imagine being able to delegate entire feature implementations to an AI, then focus your time on architecture decisions, code review, and creative problem-solving. The role of the programmer might evolve from writing code to directing and collaborating with AI systems.
Early adopters are already reporting this shift. Companies using Claude Opus 4 describe it less as a tool and more as a junior team member that happens to never get tired, never loses context, and can work through complex problems with remarkable persistence.
The hybrid reasoning approach feels particularly significant. By giving users control over when the model engages in extended thinking, Anthropic acknowledges that different tasks require different approaches. Sometimes you need a quick answer; sometimes you need careful deliberation. Having both options in a single model represents a more nuanced understanding of how people actually work.
Despite the impressive capabilities, some concerns are already emerging. The model's ability to work independently for hours raises questions about oversight and control. How do you ensure an AI stays on track during long-running tasks? What happens when it makes a wrong turn early in a complex project?
Anthropic has implemented what it calls "thinking summaries" to help users understand the model's reasoning process, but these summaries themselves are generated by AI. There's a risk of creating systems that are powerful but opaque, capable but not fully comprehensible.
This change frustrates developers who relied on seeing the model's reasoning to debug problems and refine their prompts. "It helped to see when it was going to go down the wrong track, and allowing to quickly refine the prompt to ensure it didn't," explained one user.
The shift toward hidden reasoning reflects broader industry concerns about competitive advantage and model safety. But it also represents a step away from the transparency that made earlier AI models valuable debugging and learning tools.
Have We Reached The Limits of Current AI Architectures?
Perhaps the most significant question raised by Claude 4's launch concerns the broader trajectory of AI development. Multiple developers expressed the view that "LLM progress in general has kinda stalled and we're only getting small incremental improvements from here."
This represents a dramatic shift from the exponential improvement narrative that has dominated AI discourse for the past several years. If true, it suggests we may have reached what researchers call a "capability plateau" where current architectures face fundamental limitations.
The implications extend beyond technical considerations. Much of the current AI investment boom assumes continued rapid improvement in model capabilities. If progress becomes primarily incremental, it could force a major reassessment of both business models and expectations.
For working developers, Claude 4's launch offers both opportunities and warnings. The model's improvements in software engineering tasks make it a valuable tool for certain types of work. Its integration with popular development environments like GitHub Copilot provides convenient access to enhanced AI assistance.
However, the mixed reception also serves as a reminder to maintain realistic expectations. AI coding assistants work best as productivity multipliers for experienced developers, not as replacements for deep technical knowledge. The most successful implementations focus on automating routine tasks while leaving complex architectural decisions to human experts.
Some industry observers worry about a potential "AI winter" if progress continues to slow while expectations remain high. Others argue that incremental improvements in mature technologies often prove more valuable than dramatic breakthroughs in experimental ones.
The truth likely lies somewhere between these extremes. While we may not see another GPT-3 moment anytime soon, steady improvements in reliability, efficiency, and specialized capabilities could still drive significant value creation.