AI Summary
A new study reveals that Large Language Models (LLMs) often exhibit an "English accent" when generating non-English text, using technically correct but unnaturally formal or stilted phrasing. This is attributed to LLMs being primarily designed and trained on English data, with only a small fraction of non-English content, and learning from translated texts containing "translationese" artifacts. Researchers have developed new metrics to measure this unnaturalness and demonstrated that a technique called Direct Preference Optimization (DPO).
When you chat with an AI system in a language other than English, have you ever felt something was slightly "off" about its responses? Maybe it uses accurate vocabulary and grammar, but something about the phrasing feels strangely formal or just not quite how a native speaker would express the same idea.
A
new research paper titled "Do Large Language Models Have an English 'Accent'?" suggests you're not imagining things. The study, led by Yanzhu Guo and colleagues from Apple, Inria Paris, École Polytechnique, and Sapienza University of Rome, reveals a fascinating phenomenon: today's Large Language Models (LLMs) often speak non-English languages with a distinctly "English accent."
The English-Centric AI Problem
Despite recent advances in AI capabilities, there's a significant imbalance in how different languages are represented in these systems. The researchers point out that popular models are primarily designed with English as the cornerstone language.
Consider the Llama 3.1 series of models, touted as state-of-the-art multilingual LLMs. Despite being trained on an impressive 15 trillion tokens of text, only about 8% of that training data is non-English. This imbalance has consequences.
The paper makes an apt analogy: these multilingual LLMs are like native English speakers trying to learn a new language. They bring English habits and patterns into their use of other languages, creating outputs that may be technically correct but lack natural fluency.
Another contributing factor is the common practice of exposing language models to texts translated from English during training. Both human and machine translations often contain "translationese" artifacts – subtle patterns that distinguish them from content originally written in that language.
Think about translations you've read that felt slightly awkward or stilted. That's translationese. When AI systems learn from such data, they absorb and amplify these unnatural patterns.
Measuring Naturalness in Multiple Languages
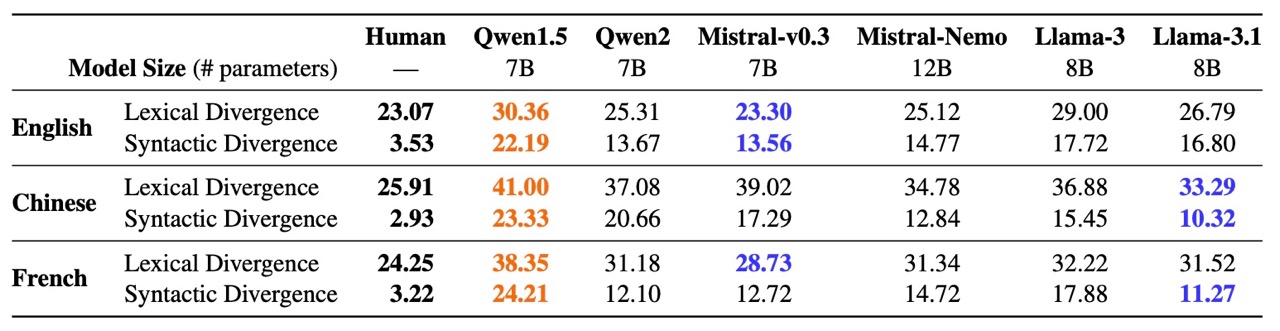
The research team's first major contribution is developing new metrics to evaluate how natural AI-generated text sounds across different languages. Unlike previous evaluations that focus primarily on task performance, these metrics examine lexical (vocabulary) and syntactic (grammar structure) distributions at the corpus level.
By comparing these distributions between AI outputs and texts written by native speakers, the researchers can quantify just how "accented" AI-generated content sounds in different languages.
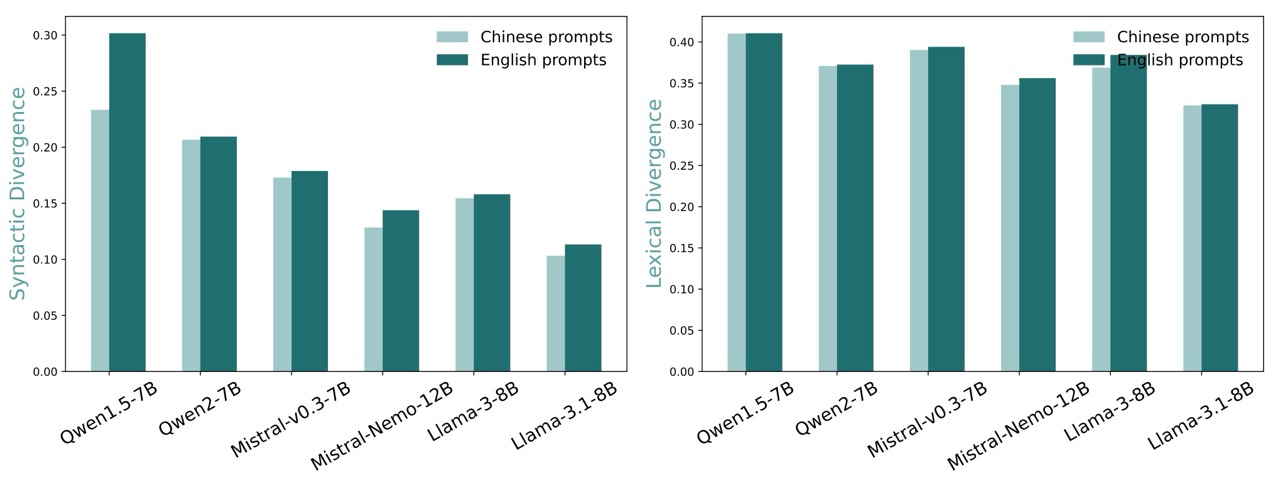
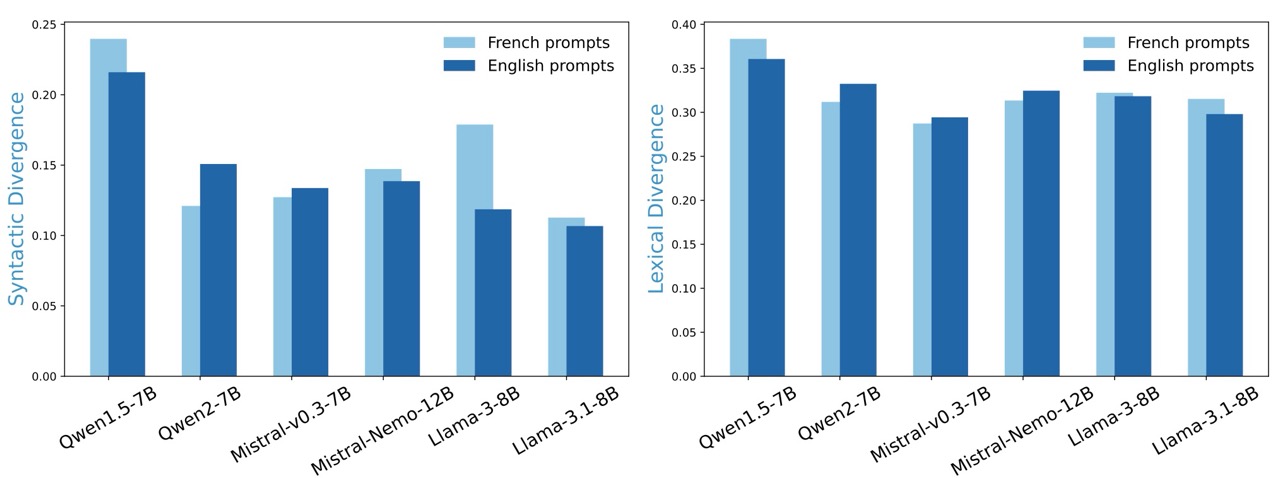
Using their newly developed metrics, the team benchmarked several state-of-the-art multilingual LLMs in English, French, and Chinese. The results confirmed what many non-English speakers have intuitively felt: these models exhibit distinct patterns that diverge from natural language use in non-English languages.
The researchers found that even the most advanced multilingual models tend to produce outputs that reflect English-influenced patterns in both vocabulary choices and grammatical structures.
Improving AI's Multilingual Naturalness
Perhaps most importantly, the paper doesn't just identify the problem – it also proposes a solution. The researchers introduce a method to enhance the naturalness of multilingual LLMs using a technique called Direct Preference Optimization (DPO).
The approach involves creating a new preference dataset that contrasts human-written responses with synthetically-manipulated ones. By training models to prefer the human-written examples, the researchers were able to significantly improve the naturalness of AI-generated Chinese text without compromising the model's performance on general benchmarks.
The implications of this research extend far beyond academic interest. As the researchers note:
As LLMs increasingly influence various aspects of our lives, their tendency to produce less natural outputs in lower-resource languages in favor of English expressions could amplify the unfairness for the communities that speak these languages.
In other words, if AI systems continue to impose English-centric linguistic patterns on other languages, they risk contributing to a form of technological language colonialism. For speakers of non-English languages, interacting with these systems could mean constantly engaging with an unnatural, foreign-accented version of their own language.
Beyond Task Performance and The Path Forward
One of the most valuable aspects of this research is how it shifts the evaluation of multilingual AI beyond simple task performance. While much attention has been paid to whether AI systems can answer questions correctly in different languages, less focus has been placed on how they deliver those answers.
The researchers argue that naturalness of expression is a crucial aspect of truly equitable AI systems. A model that can solve problems in multiple languages but always sounds like a non-native speaker is still fundamentally biased toward English speakers.
This research opens important new avenues for improving multilingual AI. By establishing metrics for naturalness and demonstrating effective methods to enhance it, the team provides a blueprint for creating more linguistically diverse and equitable systems.
Future work in this area could explore additional languages beyond the English, French, and Chinese examined in this study. It might also investigate how to better integrate native-language content during model training rather than relying heavily on translated materials.
Research Paper:
Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMsRecent Posts