geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
Apple FastVLM: New FastVLM AI Image Processing Technology on iOS Devices
AI Summary
Apple's new FastVLM system, featuring the FastViTHD hybrid architecture, offers a breakthrough by combining convolutional networks and transformers with aggressive downsampling. This innovative design drastically reduces the number of tokens processed by the costly self-attention layers, leading to significantly faster Time-to-First-Token (TTFT) and increased efficiency, particularly at high resolutions, thus enabling more responsive and powerful on-device AI vision applications.
May 13 2025 05:34
For years, AI researchers have faced a challenging dilemma: higher resolution images provide better results for many vision-language tasks, especially when dealing with text in images or fine details. However, processing these high-resolution images requires significantly more computational power and time.
Most current vision systems use what are called Vision Transformers (ViTs) to encode images before processing them with Large Language Models (LLMs). While effective, these transformers become notoriously slow at higher resolutions due to the massive number of visual tokens they generate and the computational demands of repeatedly applying self-attention mechanisms to these tokens.
The result is what users experience as lag—that frustrating wait time between asking an AI system to analyze an image and receiving the first response. Engineers call this the "Time-to-First-Token" or TTFT, and reducing it has become a primary goal for making AI systems more responsive and user-friendly.
Apple's research team has just unveiled a significant breakthrough in this arena with FastVLM, a new AI vision system that dramatically speeds up how computers "see" and process images while maintaining high accuracy.
Apple's Solution: The FastViTHD Hybrid Architecture
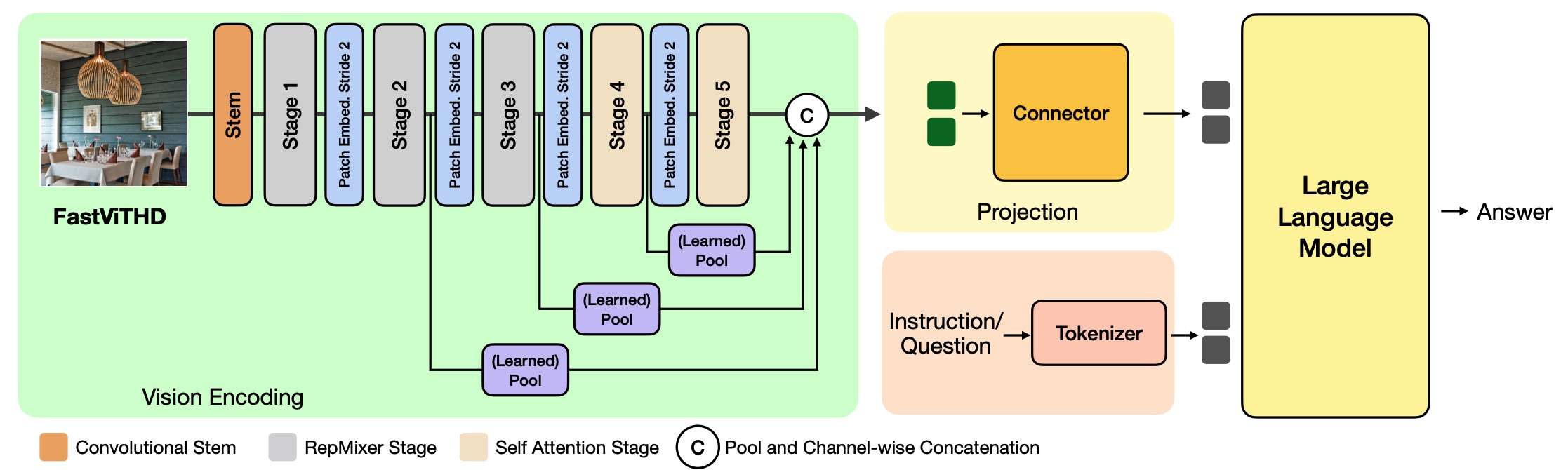
Apple's research team approached this problem with a fresh perspective. Rather than simply trying to optimize existing Vision Transformer architectures, they developed FastViTHD, a novel hybrid vision encoder that combines the strengths of convolutional neural networks (CNNs) with those of transformers.
The key innovation lies in FastViTHD's architectural design. The system uses five processing stages with the first three utilizing RepMixer blocks (a specialized type of convolutional processing) and the final two employing multi-headed self-attention mechanisms. This design allows the system to progressively downsample the image, ensuring that the computationally intensive transformer layers only need to process a fraction of the tokens that a traditional Vision Transformer would handle.
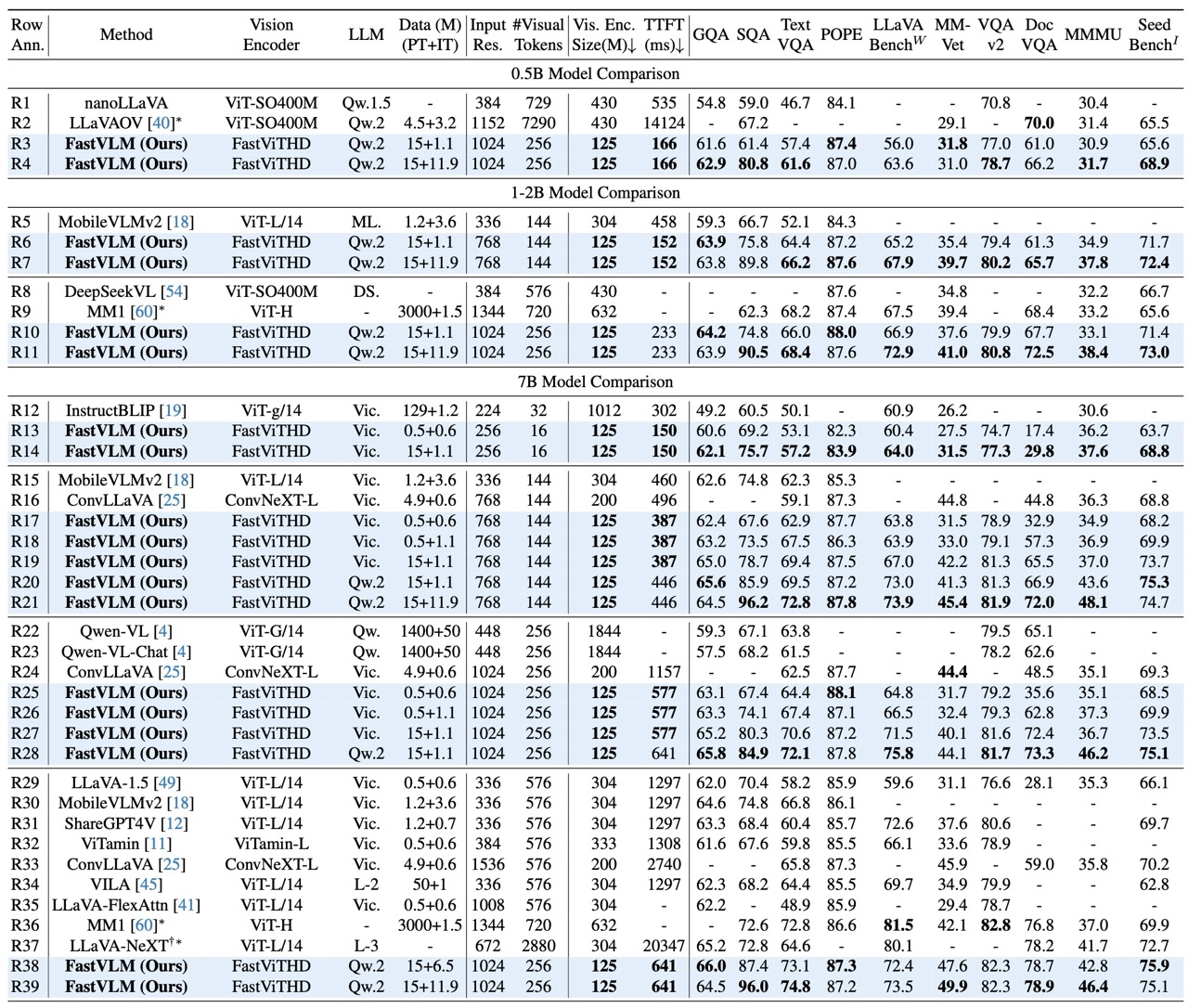
FastViTHD generates four times fewer tokens than previous hybrid approaches and a whopping 16 times fewer tokens than standard Vision Transformers, while actually improving accuracy on key benchmarks.
Remarkable Performance Gains
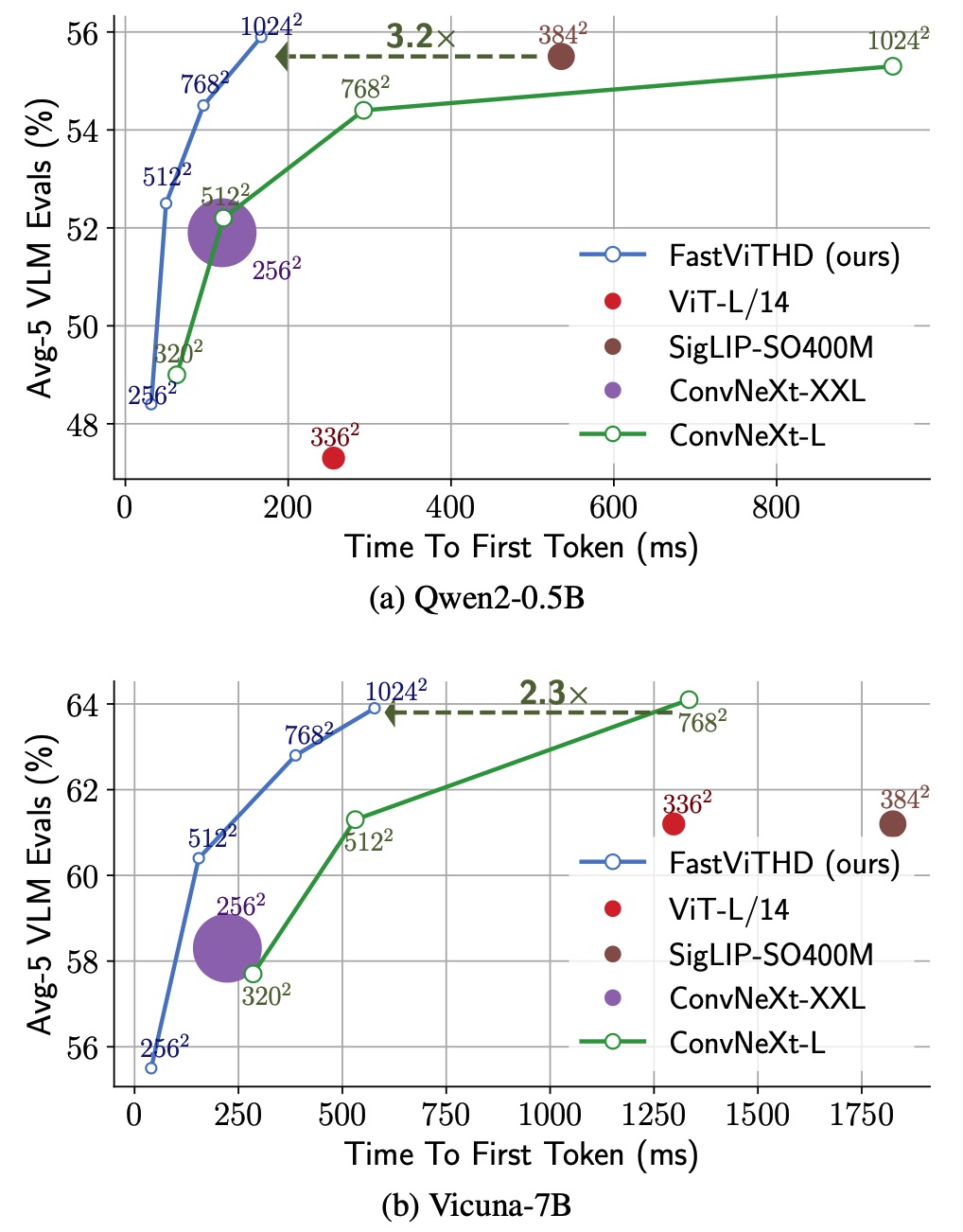
The performance improvements are striking. According to Apple's research, their smallest FastVLM variant outperforms the comparable LLaVA-OneVision-0.5B model with:
85 times faster Time-to-First-Token (TTFT)
3.4 times smaller vision encoder size
Comparable accuracy on standard benchmarks
These aren't marginal improvements—they represent a generational leap in efficiency. To put this in perspective, operations that might have taken several seconds with previous systems now complete in a fraction of a second, making real-time visual AI applications much more feasible on consumer devices.
The Science Behind the Speed
What makes FastViTHD so efficient? The secret lies in its unique architectural decisions:
Progressive downsampling: Unlike traditional Vision Transformers that maintain a constant resolution throughout processing, FastViTHD aggressively downsamples the image as it moves through its processing stages.
Strategic compute allocation: The system places self-attention layers (which are computationally expensive) only at the final stages where the image has already been downsampled by a factor of 32 or 64 on each dimension, dramatically reducing computational requirements.
Multi-scale features: FastViTHD extracts and combines information from multiple resolution scales, ensuring that important features aren't lost during the aggressive downsampling process.
Optimized for high resolutions: The entire architecture was designed specifically for efficient processing of high-resolution images, unlike many systems that were originally optimized for lower resolutions and later adapted.
Real-World Applications and Implications
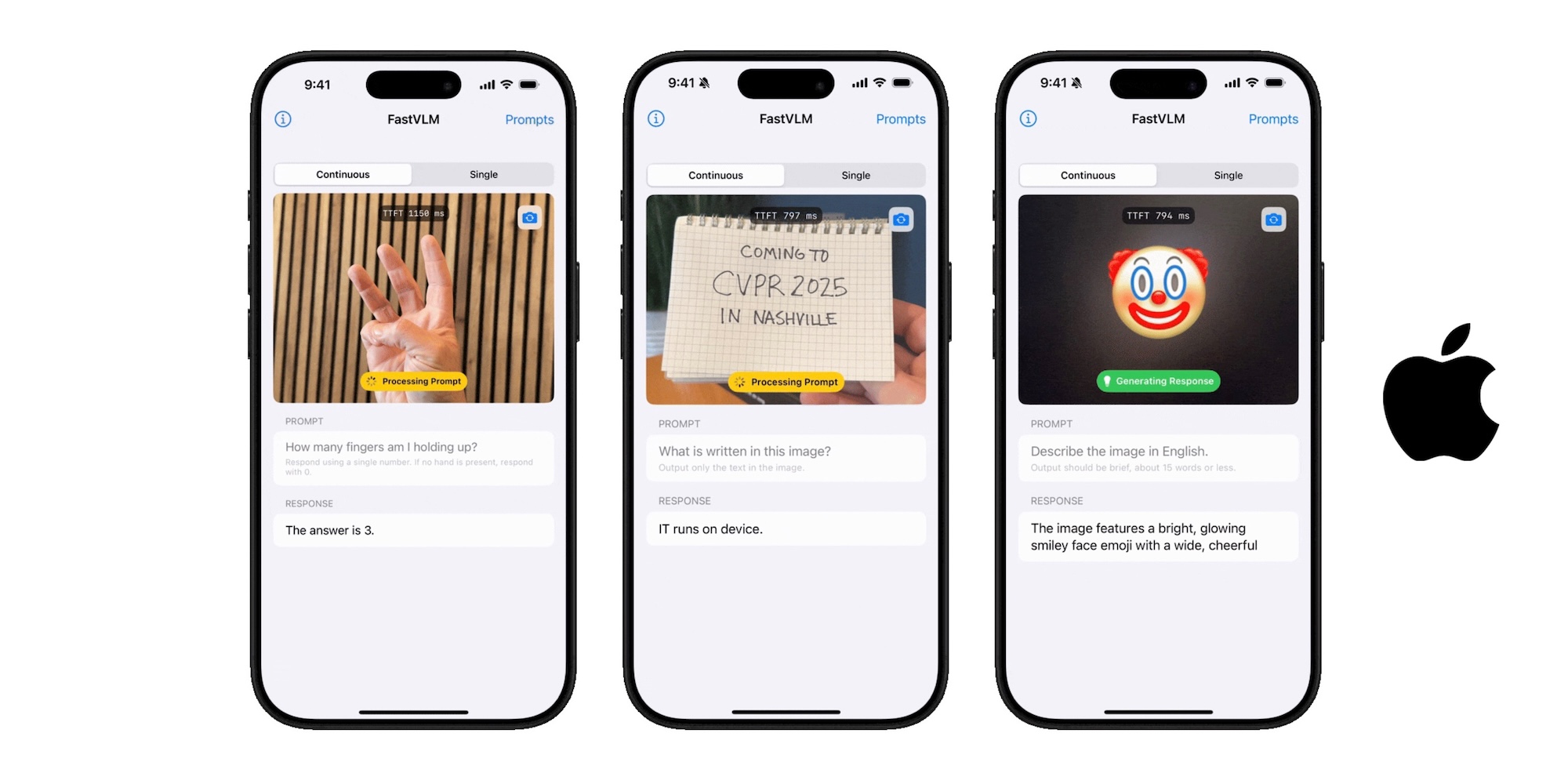
The speed improvements enabled by FastVLM could transform how we interact with AI vision systems. Apple has already demonstrated the technology running on iOS devices, showcasing how this technology could bring powerful visual AI capabilities to mobile phones and tablets without requiring cloud processing. Potential applications include:
Instantaneous document analysis for extracting and processing text from images
Real-time visual question answering about objects in the environment
Faster and more accurate image search capabilities
Improved accessibility features that can describe images to visually impaired users with minimal delay
Enhanced augmented reality experiences that require rapid visual understanding
The technology could be particularly transformative for applications that need to process text in images, such as translating foreign language signs in real-time or quickly digitizing printed documents.
One of the most promising aspects of FastVLM is how well it scales to higher image resolutions. The research demonstrates that while traditional approaches become prohibitively slow at resolutions above 512×512 pixels, FastViTHD continues to deliver reasonable performance even at resolutions as high as 1536×1536 pixels.
This scalability means that as device capabilities improve, the technology can take advantage of higher-resolution images without requiring proportional increases in processing power—a crucial consideration for deployment on consumer devices with limited computational resources.
The Broader Impact on AI Development
This focus on efficiency rather than just raw capability acknowledges the reality that many of the most important applications for AI will need to run on edge devices with limited power and processing capabilities. By dramatically reducing the resource requirements for high-quality vision processing, Apple is helping to move the field toward more accessible and practical AI systems.
While FastVLM represents a significant advance, it's just one step in the ongoing evolution of vision processing technology. Apple's research points to several promising directions for future work:
Further optimizations for even higher image resolutions
Adaptation of the architecture for video processing
Integration with smaller, more efficient language models for complete on-device visual question answering
The ultimate goal is clear: to make sophisticated visual AI accessible and responsive enough to become an integral part of our daily digital experiences, rather than a specialized tool that we only occasionally utilize.