geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
The Stable Diffusion Moment for Open Source AI Music Generation Has Arrived
AI Summary
ACE-Step, an open-source foundation model, marks a potential watershed moment for AI music generation by tackling the long-standing trilemma of generation speed, musical coherence, and user controllability that has limited previous approaches. Unlike slow but coherent LLM-based models or fast but structurally weak diffusion models, ACE-Step uniquely combines diffusion-based generation for speed, a deep compression autoencoder for efficient latent representation, a lightweight transformer for long-range planning, and semantic alignment techniques for precise control.
May 07 2025 16:17
The world of AI-generated music is experiencing a watershed moment with the arrival of ACE-Step, an open-source foundation model that promises to do for music what Stable Diffusion did for images. Created by researchers Junmin Gong, Sean Zhao, Sen Wang, Shengyuan Xu, and Joe Guo, this innovative system tackles the fundamental limitations that have held back AI music generation until now. Here is the generated song with tags "electronic, rock, pop" and the following lyrics:
(Verse 1) 🎵🎵🎵 It’s not just a dream, it’s the start of a way, Building the future where music will play. A model that listens, a model that grows, ACE-Step is the rhythm the new world knows.
(Pre-Chorus) No more limits, no more lines, A thousand songs in a million minds. We light the spark, we raise the sound, A new foundation breaking ground.
(Chorus) ACE-Step, we take the leap, Into a world where the music speaks. Fast and free, we shape the skies, Creating songs that never die. ACE-Step — the beat goes on, Foundation strong, a brand-new dawn. 🎵🎵🎵
(Verse 2) 🎵 Not just end-to-end, but a canvas to paint, A million colors, no need to wait. For every artist, for every sound, ACE-Step lays the sacred ground.
(Pre-Chorus) 🎵 No more limits, no more lines, A thousand songs in a million minds. We light the spark, we raise the sound, A new foundation breaking ground.
(Chorus) 🎵 ACE-Step, we take the leap, Into a world where the music speaks. Fast and free, we shape the skies, Creating songs that never die. ACE-Step — the beat goes on, Foundation strong, a brand-new dawn.
(Bridge) 🎵 From every beat to every rhyme, We build the tools for endless time. A step, a song, a dream to keep, ACE is the promise we will leap.
(Final Chorus) 🎵 ACE-Step, we take the leap, Into a world where the music speaks. Fast and free, we shape the skies, Creating songs that never die. ACE-Step — the beat goes on, Foundation strong, a brand-new dawn. ACE-Step — the future’s song.
Until now, AI music generation has faced a seemingly insurmountable trilemma. Existing approaches have forced developers and users to choose between:
Generation speed: How quickly can the AI produce a complete piece?
Musical coherence: Does the music maintain consistent themes and structures?
Controllability: Can users guide and shape the creative output?
This trade-off has limited the practical applications of AI music generation, particularly for professional creators who need both quality and speed in their workflow. To understand why ACE-Step represents such a breakthrough, we need to examine the strengths and limitations of the current state of AI music generation.
LLM-based Models: Coherence at the Cost of Speed
Models like YuE and SongGen leverage the sequential processing power of Large Language Models to create musically sophisticated outputs. Their strengths are immediately apparent to listeners:
The vocal melodies feel natural and singable, with notes precisely aligned to syllables and lyrical emphasis
Songs maintain coherent structures throughout their duration, following recognizable patterns like verse-chorus-verse
Musical themes develop logically, with thoughtful harmonic progressions and thematic callbacks
YuE specifically designed for the lyrics-to-song task, maintains this lyrical alignment even over extended compositions.
SongGen similarly excels at capturing the complex relationship between words and melody that makes vocal music feel authentic rather than mechanical.
The price for this coherence, however, is steep. These models generate music token by token in an autoregressive fashion—essentially composing note by note, like a human musician might—which makes them painfully slow. A three-minute composition might take nearly five minutes to generate, making real-time applications or rapid experimentation impossible.
Despite their impressive coherence, these models aren't without flaws. They frequently produce structural artifacts—repetitive patterns, awkward transitions, or formulaic progressions that betray their algorithmic origins. These aren't always deal-breakers, but they create that subtle "uncanny valley" effect where the music feels almost—but not quite—human.
Diffusion Models: Speed Without Structure
On the opposite end of the spectrum, diffusion-based approaches like DiffRhythm offer a tantalizing glimpse of what high-speed music generation can achieve. By denoising random signals through parallel processing rather than sequential generation, these models can produce full songs in mere seconds—what the creators of DiffRhythm describe as "blazingly fast" inference.
This speed advantage makes diffusion models particularly attractive for applications requiring rapid iteration or real-time generation. A musician could experiment with dozens of variations in the time it would take an LLM-based model to produce a single option.
However, this velocity comes with significant trade-offs in long-range musical coherence. While diffusion models excel at generating convincing short musical phrases and textures, they often struggle to maintain a consistent musical identity over longer durations. This manifests as fragmented musical structures, abrupt stylistic shifts, or a lack of thematic development—similar to how AI-generated images might look convincing at first glance but reveal anatomical impossibilities upon closer inspection.
The result is music that sounds locally plausible but globally disjointed—technically perfect in each moment but lacking the overarching narrative that makes a composition feel intentional and complete. DiffRhythm's documentation acknowledges these challenges, highlighting efforts to maintain musicality over several minutes, but the fundamental limitation remains.
ACE-Step: Bridging the Impossible Gap
This is where ACE-Step enters the scene as a genuine breakthrough. Rather than accepting the traditional trade-offs or making incremental improvements to existing approaches, the research team took a fundamentally different path: integrating seemingly contradictory architectural elements into a harmonious whole. ACE-Step's innovation lies in its holistic architectural approach that combines four key components:
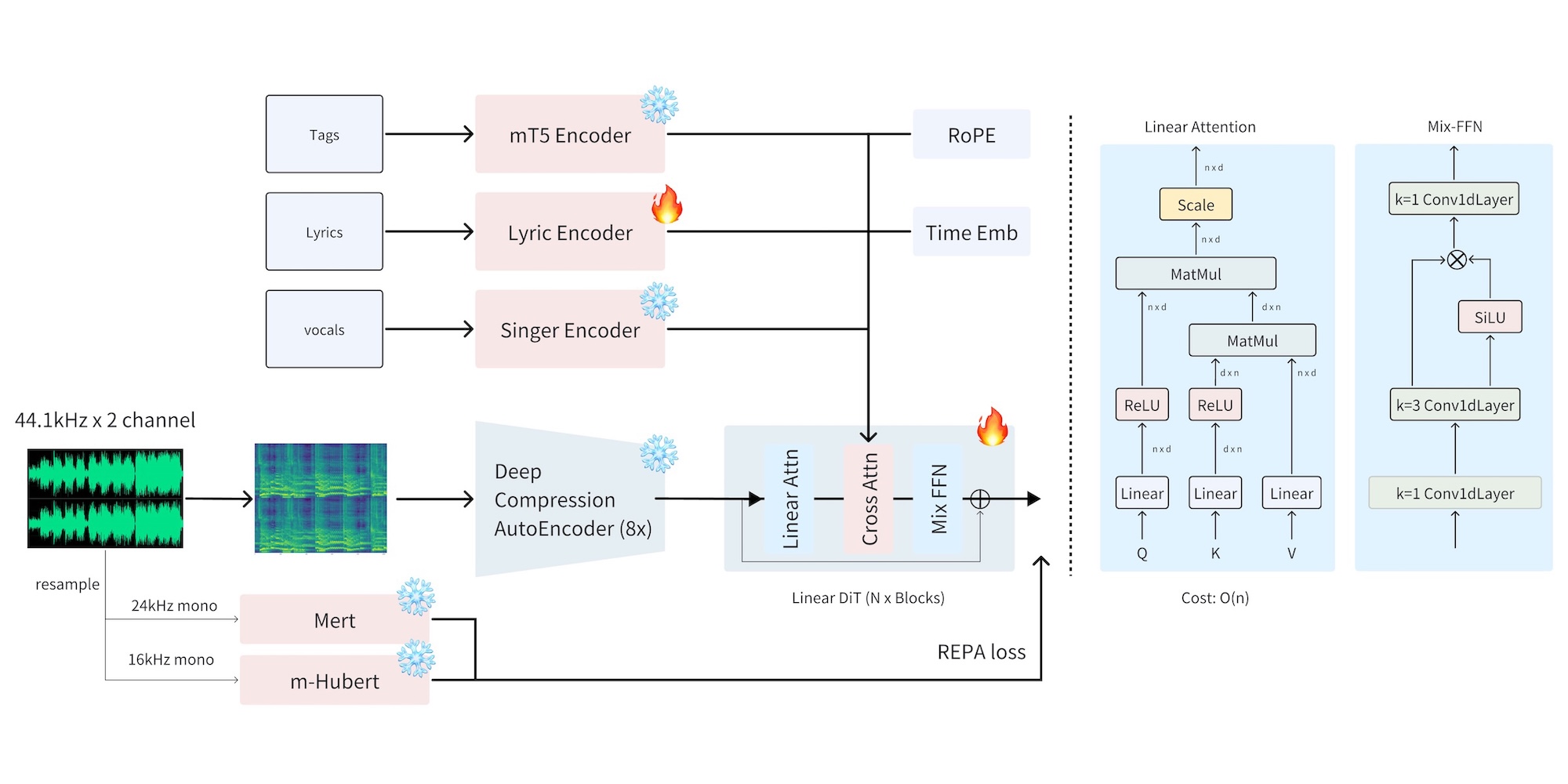
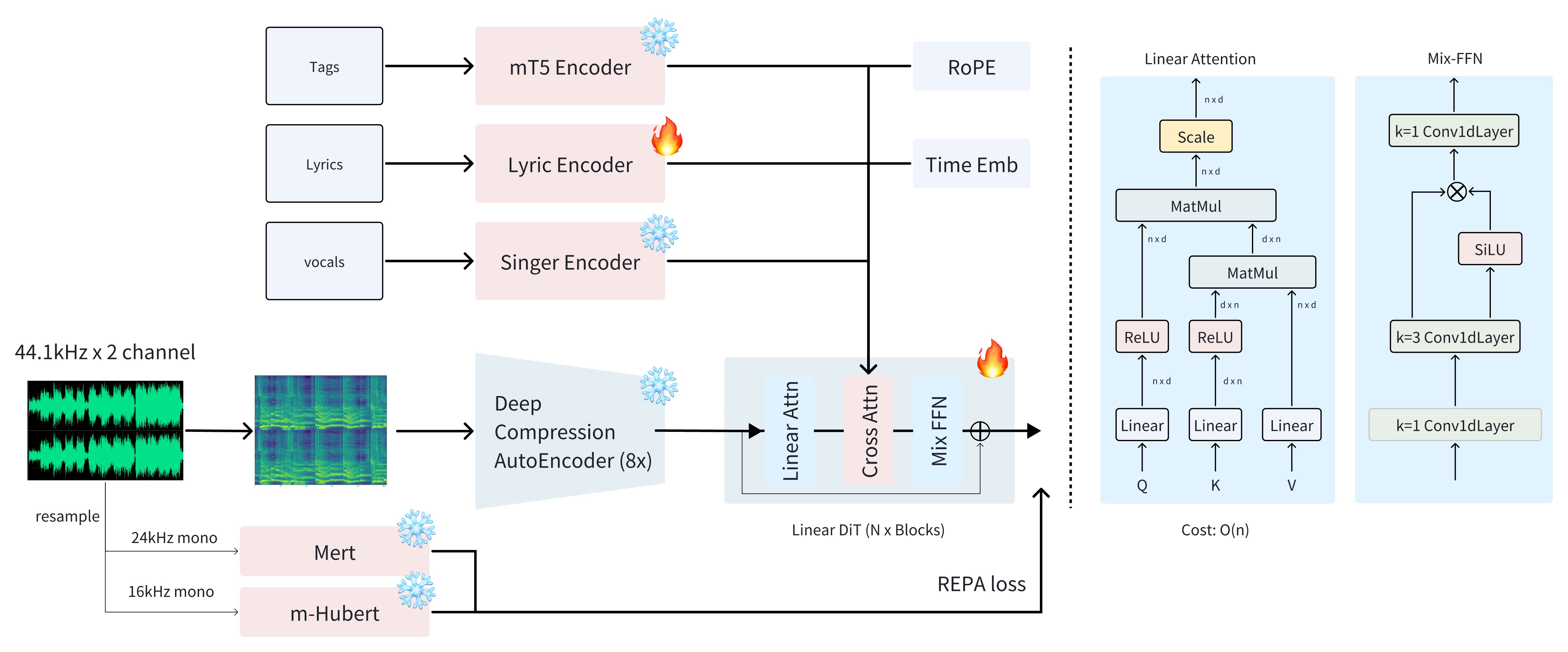
Diffusion-based generation provides the speed foundation, generating audio efficiently without the token-by-token limitations of autoregressive methods
Sana's Deep Compression AutoEncoder (DCAE) creates an efficient latent representation of music, preserving the essential characteristics while simplifying the generation space
A lightweight linear transformer introduces the long-range planning and coherence typically associated with LLMs, but without their computational overhead
MERT and m-hubert alignment techniques (REPA) create semantic bridges between text, melody, and rhythm, enabling precise control over musical elements
This architectural symphony allows ACE-Step to synthesize up to 4 minutes of music in just 20 seconds on an A100 GPU—a staggering 15 times faster than LLM-based approaches. More importantly, it achieves this without sacrificing musical coherence or controllability, scoring higher on metrics for melody, harmony, and rhythm than models specialized in those individual areas.
"We designed ACE-Step to be the foundation model for music AI," explains one of the researchers. "Rather than building yet another end-to-end text-to-music pipeline, we wanted to create a fast, general-purpose architecture that makes it easy to train sub-tasks on top of it. It's about providing the foundation for an ecosystem rather than a single application."
Speed Without Sacrifice: The Technical Deep Dive
At the heart of ACE-Step's remarkable achievement lies its multi-modal approach to music generation—an intricate dance of complementary technologies that strengthen each other's weaknesses while amplifying their inherent strengths.
The integration of Sana's Deep Compression AutoEncoder (DCAE) represents a crucial breakthrough. Unlike conventional approaches that work with raw audio or simplistic symbolic representations, DCAE creates a highly efficient latent space for music—a compressed dimensional representation that preserves the essential characteristics of melody, harmony, timbre, and rhythm while stripping away unnecessary complexity. This compression not only accelerates processing but creates a more manageable "creative space" for the diffusion process to operate within.
Where ACE-Step truly transcends its predecessors is in its preservation of fine-grained acoustic details—the subtle variations in timbre, expression, and articulation that give music its emotional resonance. This attention to nuance, combined with the model's sophisticated understanding of musical structure, enables a suite of advanced control mechanisms that transform ACE-Step from a mere generator into a versatile creative partner:
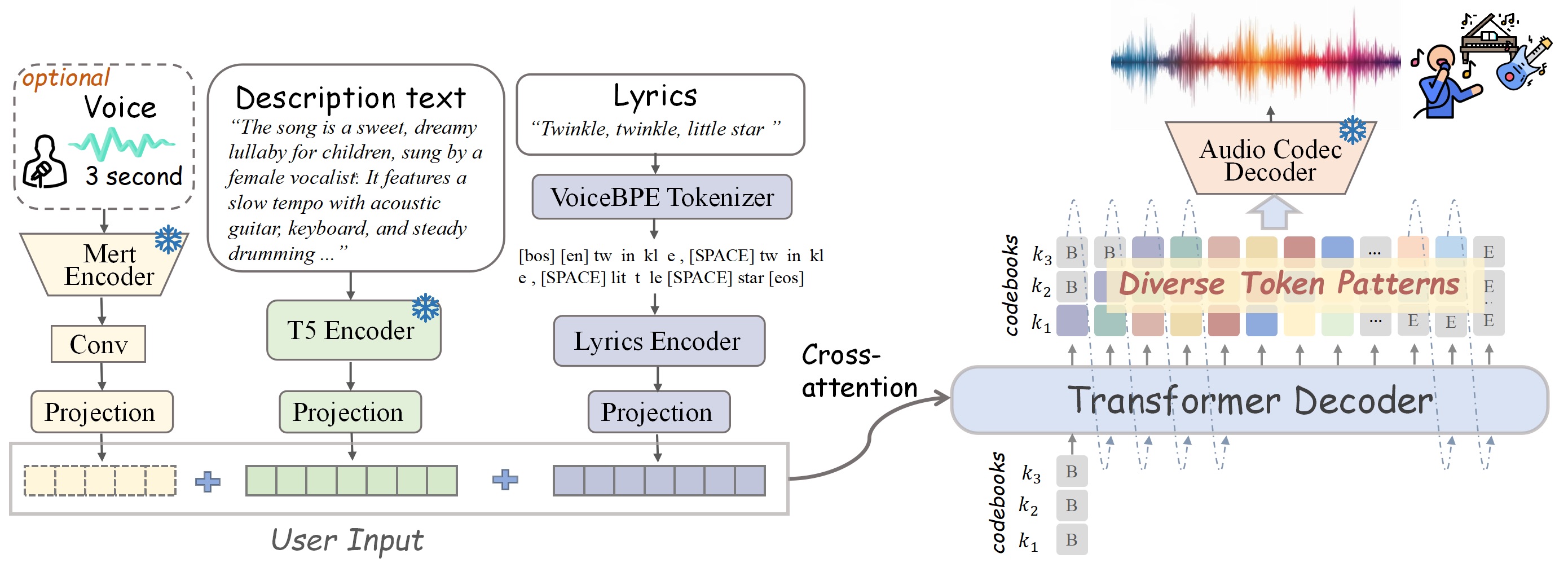
Voice cloning: Capture the distinctive timbre and stylistic fingerprint of a vocalist, allowing for the creation of new performances that maintain their unique vocal identity. Unlike simple mimicry, ACE-Step preserves subtle characteristics like vibrato patterns, breath control, and distinctive pronunciation that define a singer's recognizable sound.
Lyric editing: Modify words or entire phrases while preserving the musical integrity of a piece. ACE-Step intelligently adapts melody lines to accommodate new syllable counts and stress patterns, ensuring natural-sounding vocal lines regardless of textual changes.
Remixing: Transform existing compositions while preserving their core musical identity—change the genre, instrumentation, or tempo while maintaining recognizable themes and progressions. This capability lets creators explore alternative interpretations of their work without starting from scratch.
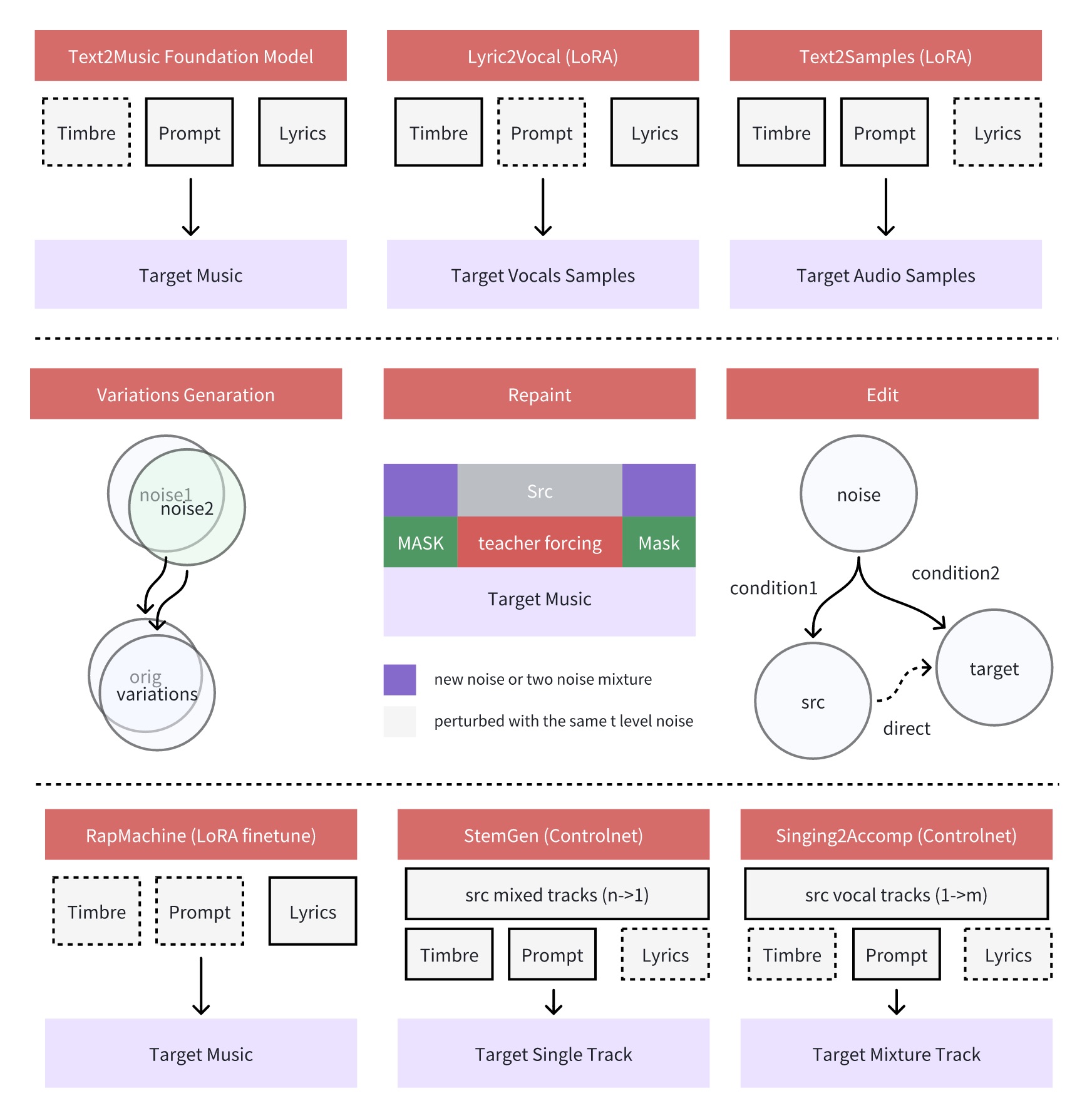
Component generation: Create specific instrumental or vocal elements for a composition through targeted generation pathways like lyric2vocal (creating vocal performances from text) or singing2accompaniment (generating complementary instrumental backgrounds for existing vocal lines).
ACE-Step also supports text-to-audio generation across 17 languages:
English
Chinese
German
French
Spanish
Italian
Portuguese
Polish
Turkish
Russian
Czech
Dutch
Arabic
Japanese
Hungarian
Korean
Hindi
This extensive language support democratizes music creation across cultural and linguistic boundaries, enabling creators worldwide to generate music in their native language. The multilingual capability is particularly significant for vocal music generation, allowing for proper pronunciation, intonation, and lyrical flow specific to each language's unique phonetic characteristics.
The Stable Diffusion Moment for Music
The comparison to Stable Diffusion is not just marketing hyperbole. Just as Stable Diffusion revolutionized image generation by providing an open-source, efficient, and flexible architecture, ACE-Step aims to do the same for music generation. The key parallels include:
Open-source accessibility: Available on GitHub and Hugging Face
Efficiency: Dramatically faster generation than previous approaches
Flexibility: Designed as a foundation model for multiple music-related tasks
Quality: Achieving state-of-the-art results across multiple metrics
This combination of factors positions ACE-Step to become the go-to foundation model for music AI development, potentially sparking an ecosystem of tools and applications built on top of its architecture. Its practical applications include:
Assisting composers with background music generation
Creating customized music for content creators and streamers
Developing interactive music experiences for games and VR
Enabling non-musicians to express musical ideas
Accelerating the music production process for professionals
For the music industry, this represents both an opportunity and a challenge. On one hand, ACE-Step could democratize music creation and unlock new creative possibilities. On the other, it raises questions about copyright, originality, and the role of human creativity in an increasingly AI-assisted landscape.
The Technical Roadmap and Future Development
The ACE-Step team has emphasized that this release is just the beginning. Their roadmap includes:
RapMachine represents a fascinating specialized implementation of ACE-Step fine-tuned exclusively on rap data. Unlike general music generation systems, RapMachine is being designed to master the unique cadence, flow, and linguistic patterns that define hip-hop as an art form. The team envisions AI rap battles where the system can respond contextually to topics and styles, as well as narrative expression through cohesive verses that tell compelling stories—a hallmark of the greatest rap artists.
StemGen Precision Instrument Generation specialized implementation functions as a controlnet-lora trained on multi-track data, enabling the generation of specific instrumental elements that perfectly complement existing compositions.
Singing2Accompaniment essentially reverses the StemGen process to generate a complete mixed master track from nothing more than a vocal recording. This tool promises to democratize music production by allowing anyone with a voice to create professional-sounding complete tracks.
As with any foundation model, the true potential of ACE-Step will emerge as developers build specialized tools and applications on top of its architecture. The team has specifically designed ACE-Step to facilitate this ecosystem development, providing comprehensive documentation and examples.
ACE-Step represents a significant leap forward in AI music generation, potentially marking the beginning of a new era where AI becomes an integral part of the music creation process. By solving the fundamental trilemma of speed, coherence, and control, it opens up possibilities that were previously unattainable.