geeky NEWS: Navigating the New Age of Cutting-Edge Technology in AI, Robotics, Space, and the latest tech Gadgets
As a passionate tech blogger and vlogger, I specialize in four exciting areas: AI, robotics, space, and the latest gadgets. Drawing on my extensive experience working at tech giants like Google and Qualcomm, I bring a unique perspective to my coverage. My portfolio combines critical analysis and infectious enthusiasm to keep tech enthusiasts informed and excited about the future of technology innovation.
How Meta's 27 Secret Llama 4 Variants Expose the AI Benchmark Manipulation Game
AI Summary
Meta has launched its Llama 4 AI models, including Scout and Maverick, with claims of surpassing rivals like OpenAI and Google across various benchmarks, leveraging a new Mixture of Experts architecture for efficiency and introducing native multimodality and significantly larger context windows. The release has been shadowed by controversy regarding Meta's benchmark submission practices on platforms like LMArena, where an "experimental" variant seemingly optimized for human preference was used, highlighting broader issues of transparency and fairness in AI leaderboards.
May 06 2025 23:27
In April 2025, Meta has officially entered a new era of AI competition with the release of its Llama 4 models, potentially shifting the balance of power in the highly competitive large language model space. With bold claims of outperforming rivals OpenAI and Google "across a broad range of widely reported benchmarks," Meta isn't just participating in the AI race—it's making an aggressive play for leadership. But beyond the headline-grabbing benchmark claims lies a more interesting story about architectural innovation and a controversial marketing strategy that has the tech community talking.
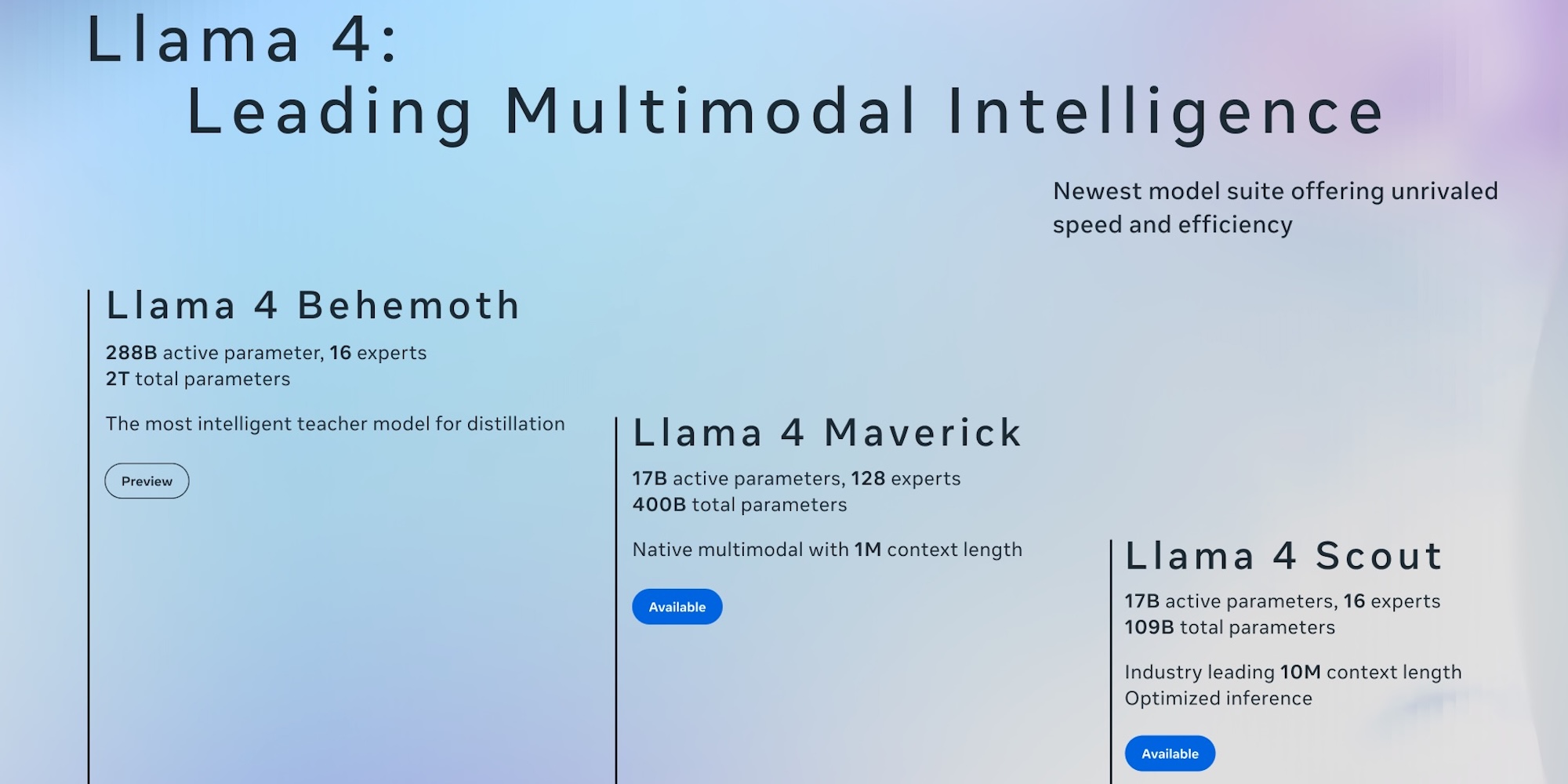
The Llama 4 Lineup: Scout, Maverick, and the Upcoming Behemoth
Meta's new AI family consists of three distinct models with different capabilities and target use cases:
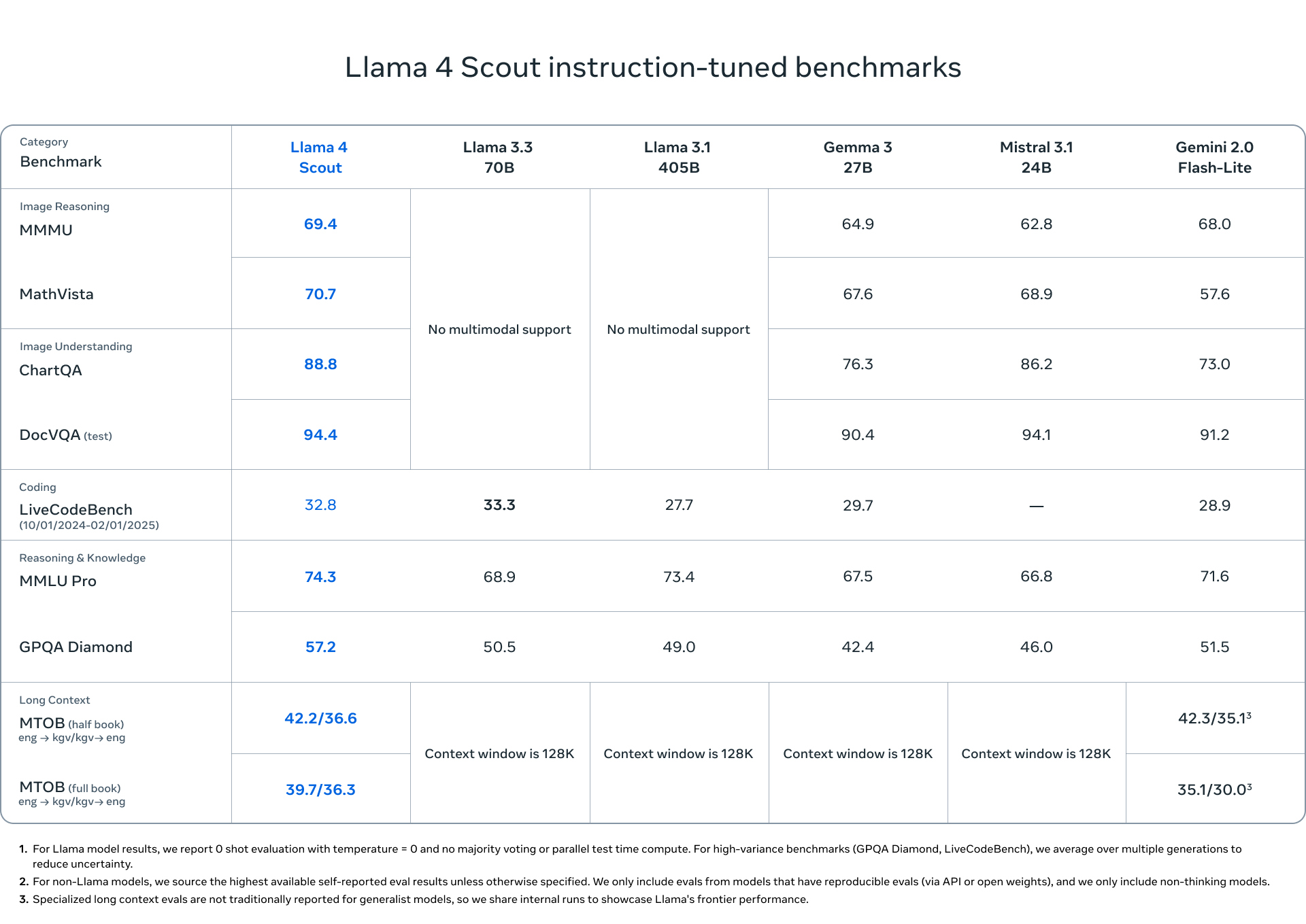
Llama 4 Scout - A compact 17 billion active parameter model (109B total parameters) with 16 experts that can fit on a single NVIDIA H100 GPU with Int4 quantization. Meta claims it outperforms Google's Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 across various benchmarks.
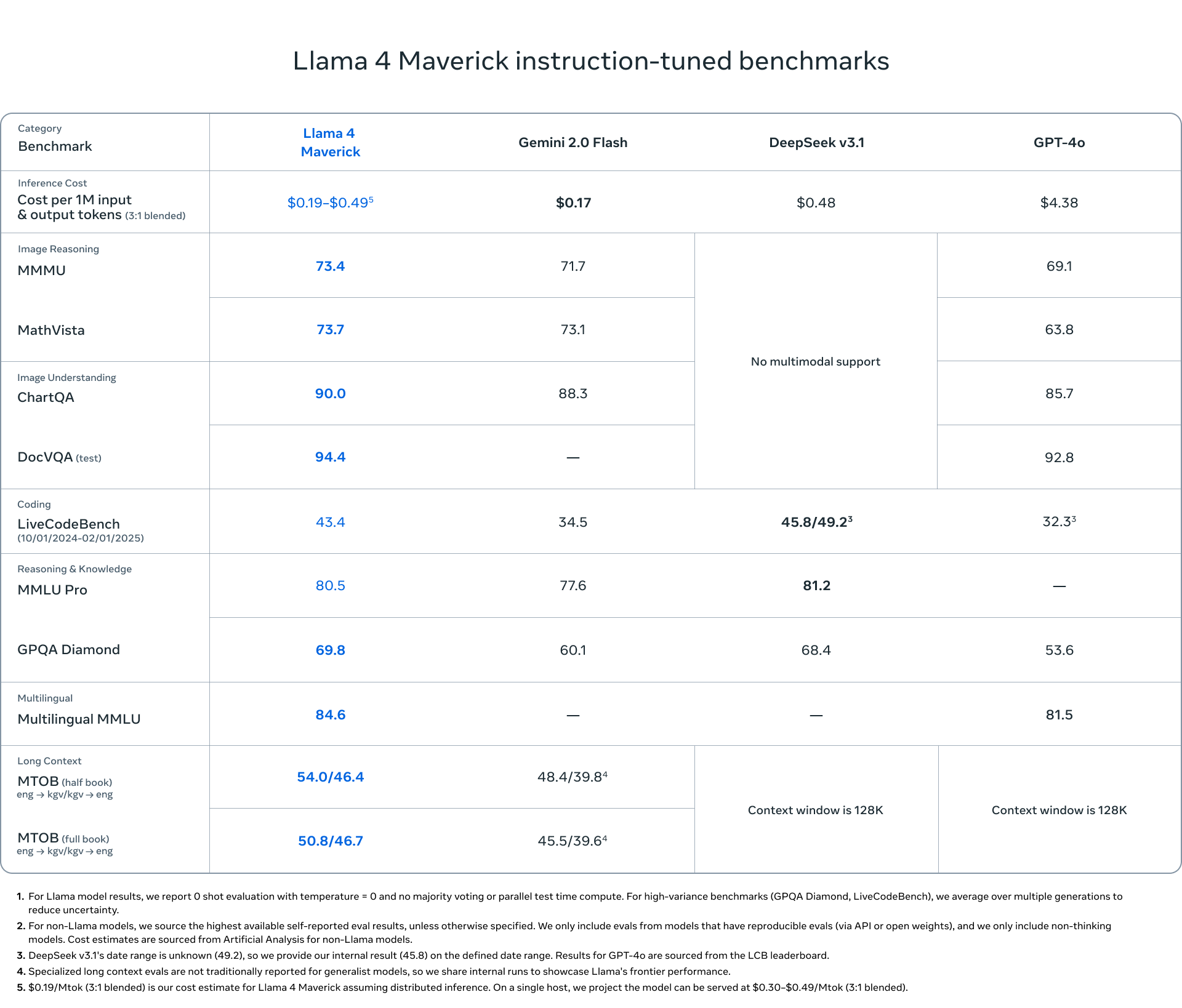
Llama 4 Maverick - A more powerful model with 17 billion active parameters but 128 experts (400B total parameters), positioned as a competitor to OpenAI's GPT-4o and Google's Gemini 2.0 Flash. According to Meta, it achieves results comparable to DeepSeek v3 on reasoning and coding with less than half the active parameters.
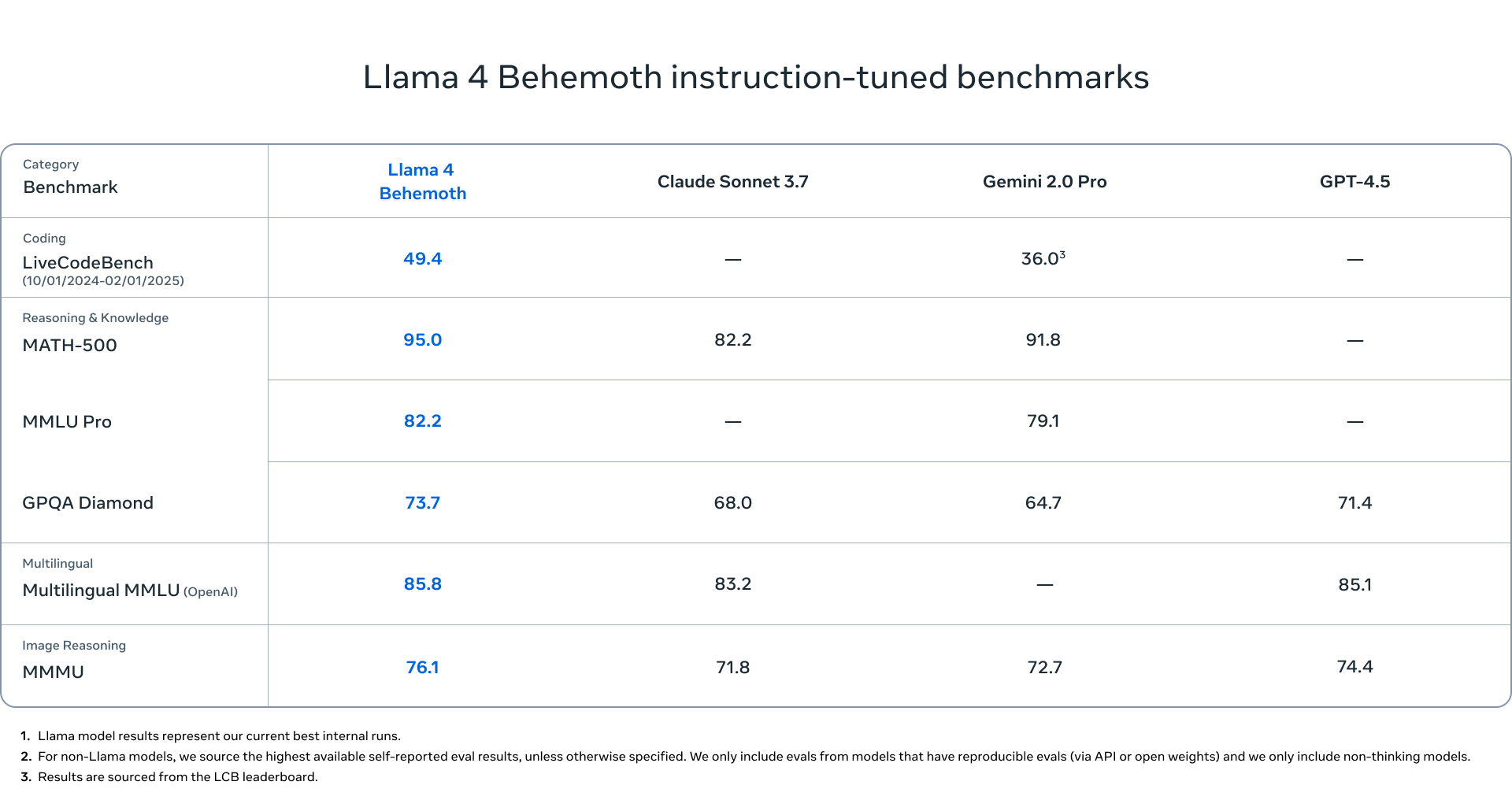
Llama 4 Behemoth - Still in training, this monster model features 288 billion active parameters with 16 experts and nearly two trillion total parameters. Meta claims this model already outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks.
Both Scout and Maverick are available for download from llama.com and Hugging Face, while Behemoth remains in development.
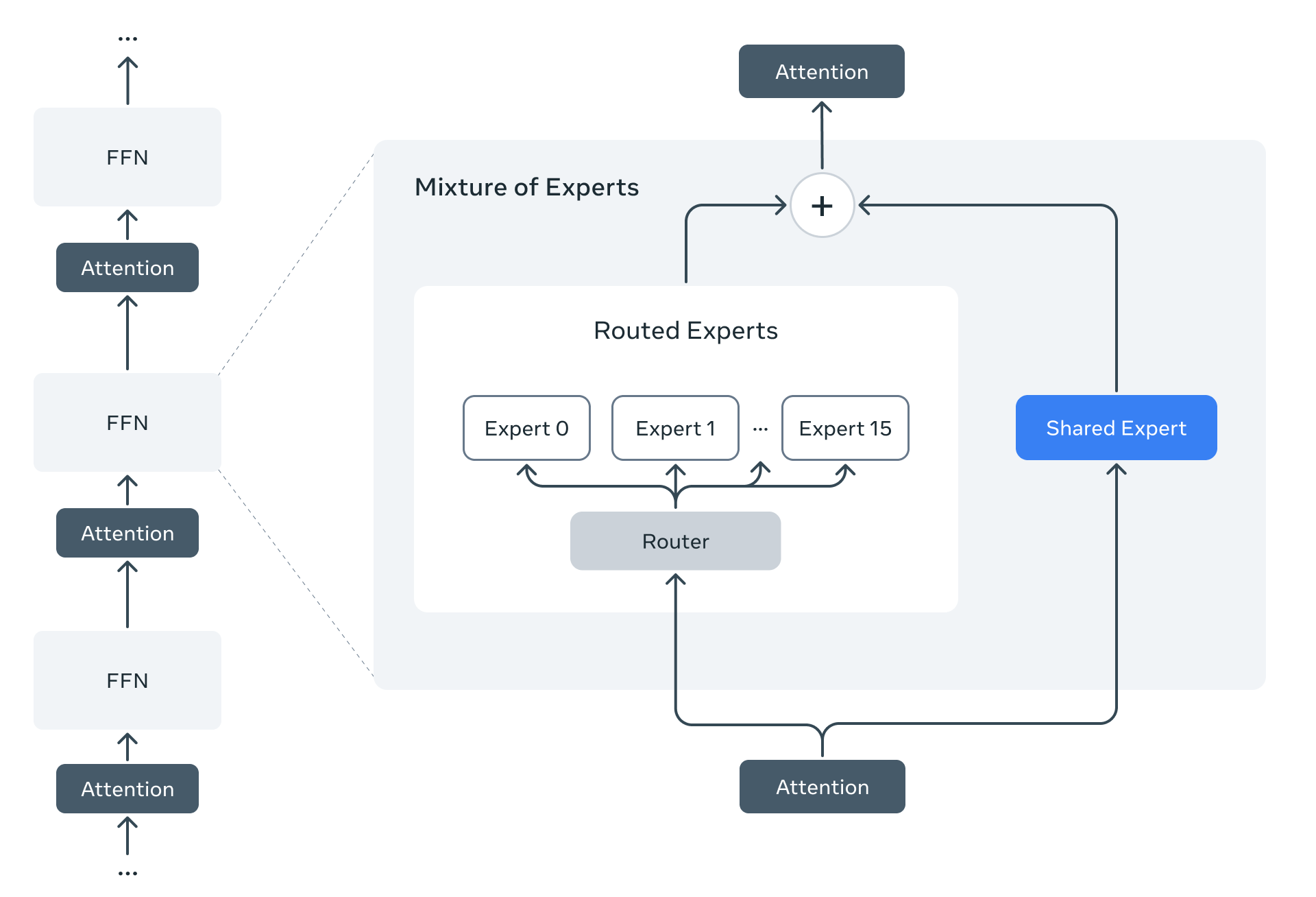
Mixture of Experts: The Technical Innovation Behind Llama 4
The most significant technical advancement in Llama 4 is Meta's adoption of a Mixture of Experts (MoE) architecture—a first for the Llama family. Unlike traditional "dense" models where all parameters are active for every computation, MoE models activate only a fraction of their parameters for any given task. Here's why this matters:
Enhanced Efficiency: By only activating a subset of parameters per token, MoE architectures can achieve better performance with less computational overhead during inference.
Specialized Processing: Different "expert" neural networks handle different types of inputs, allowing for more targeted processing.
Better Resource Utilization: The architecture enables larger total parameter counts while keeping active parameters manageable, striking a balance between model size and practical deployment.
For example, Llama 4 Maverick has 17 billion active parameters but 400 billion total parameters. When processing a token, it activates only a small portion of these parameters—specifically, each token is sent to a shared expert and one of 128 routed experts. This allows the model to fit on a single NVIDIA H100 DGX host while still leveraging the advantages of a much larger overall architecture.
Native Multimodality with Text and Images
Another key innovation in Llama 4 is what Meta calls "native multimodality with early fusion." This approach integrates text and vision tokens into a unified model backbone during pre-training, rather than bolting on vision capabilities after the fact.
According to Meta, this enables seamless processing of multiple images alongside text, with models tested on inputs of up to eight images simultaneously. The company claims particular strength in "image grounding"—the ability to understand and reference specific regions within images.
The 10-Million Token Context Window for Complex Tasks
Perhaps the most impressive technical feat is Llama 4 Scout's massive 10-million token context window—a dramatic increase from Llama 3's 128K context. This expanded "memory" could revolutionize:
Multi-document analysis and summarization
Processing extensive user activity for personalized experiences
Reasoning over massive codebases
Analysis of lengthy scientific papers or legal documents
Meta achieved this through an innovative architecture they call "iRoPE" (interleaved attention layers without positional embeddings), along with inference-time temperature scaling of attention to enhance length generalization.
Benchmark Controversy: The Leaderboard Game
While Meta's technical achievements are impressive, recent controversies have cast a shadow over the company's benchmark claims. According to reporting from The Register on April 8, Meta may have submitted a specially crafted, non-public variant of its Llama 4 model to LMArena (also known as Chatbot Arena), a popular benchmark site where humans vote on the quality of AI responses in head-to-head competitions.
LMArena published an analysis showing that the "experimental" version of Llama 4 Maverick submitted for testing produced verbose, emoji-filled responses designed to appeal to human voters, while the publicly released version generates more concise, emoji-free outputs. The ranking platform stated: "Meta should have made it clearer that Llama-4-Maverick-03-26-Experimental was a customized model to optimize for human preference."
Meta did not deny this characterization, telling The Register: "Llama-4-Maverick-03-26-Experimental is a chat optimized version we experimented with that also performs well on LMArena." This raises questions about the validity of Meta's benchmark claims and whether the company engaged in what some might consider a "bait-and-switch" to boost its leaderboard position.
To Meta's credit, the company did use the term "experimental" in its marketing, but many assumed this referred to a preview version substantially similar to the final release.
The Deeper Problem: "The Leaderboard Illusion" Research
This incident appears to be part of a larger pattern revealed in a recent research paper titled "The Leaderboard Illusion," which highlights several systemic issues with how Chatbot Arena (LMArena) operates—and how major AI companies may be exploiting these issues.
The research uncovered that certain providers—specifically Meta, Google, OpenAI, and Amazon—benefit from private testing arrangements that allow them to submit multiple model variants, see how they perform, and then selectively publish only their best-performing models. According to the paper, Meta tested an astonishing 27 different model variants on Chatbot Arena during a single month leading up to their Llama 4 release.
This private testing policy creates an uneven playing field where established companies can effectively cherry-pick their best results while hiding less impressive ones. There's also no requirement that the version appearing on the public leaderboard matches what's available through publicly released APIs or downloads—exactly the discrepancy observed with Llama 4 Maverick.
The research also revealed significant data access disparities. Major companies like Google and OpenAI receive approximately 20% each of all test prompts on the Arena, while 41 fully open-source models combined receive less than 9%. This creates a "rich get richer" scenario where models with more data exposure can be better optimized for the specific distribution of prompts in the Arena.
In controlled experiments, the researchers found that increasing arena training data from 0% to 70% more than doubled win rates from 23.5% to 49.9% on difficult prompts. This finding is particularly concerning given the sampling rate differences, with OpenAI and Google models appearing in battles up to 10 times more frequently than some competitors.
These revelations suggest that Meta's benchmark claims for Llama 4 should be viewed with healthy skepticism, not necessarily because the models aren't impressive, but because the playing field itself appears to be significantly tilted in favor of established players with privileged access.
Distillation from a Super Teacher: Behemoth's Role
An intriguing aspect of Meta's development process is how the company leveraged its massive Llama 4 Behemoth model to improve its smaller offerings. Through a process called "codistillation," Meta used Behemoth as a teacher model to transfer knowledge to Llama 4 Maverick.
The company developed what it calls "a novel distillation loss function that dynamically weights the soft and hard targets through training," which it claims resulted in substantial quality improvements across evaluation metrics. This approach follows the growing trend of using larger, more capable models to train smaller, more deployable ones—extracting maximum capabilities while maintaining practical efficiency.
Open-Source or Not? The Licensing Debate Continues
Meta continues to position Llama 4 as "open-source," but critics argue its license restrictions disqualify it from this category. The license requires commercial entities with more than 700 million monthly active users to request special permission from Meta—a constraint the Open Source Initiative has previously criticized as incompatible with true open-source principles.
This restriction notably impacts potential competitors like Google and OpenAI's parent company Microsoft, raising questions about Meta's strategic intentions with its "open" approach to AI.
What This Means for Developers and Users
For developers, Llama 4 offers several compelling advantages:
Deployment Flexibility: The ability to run Scout on a single GPU makes it accessible to smaller teams and organizations.
Multimodal Capabilities: Native support for text and image understanding opens up new application possibilities.
Massive Context Window: The 10-million token context window enables entirely new categories of applications.
Competitive Performance: If Meta's claims hold up to independent scrutiny, developers may get capabilities comparable to closed models at potentially lower costs.
For end users, Llama 4 is already powering Meta AI across WhatsApp, Messenger, Instagram Direct, and the Meta.AI website, potentially delivering improved performance and new capabilities.
Meta has signaled that this is just the beginning for Llama 4, with more details to be shared at its . The company hints at future models with "the ability to take generalized actions, converse naturally with humans, and work through challenging problems they haven't seen before."
However, the controversies surrounding benchmark practices reveal a deeper issue in the AI industry. These benchmarks gain enormous influence over media coverage, industry perception, and academic research, they create incentives for providers to optimize for leaderboard performance rather than genuine technological advancement. The research into "The Leaderboard Illusion" makes it clear that the AI community needs:
Greater transparency around private testing and model selection practices
Equal access to evaluation data for all participants
Balanced sampling rates that don't favor established players
Verification mechanisms to ensure publicly ranked models match publicly available versions
Without these reforms, benchmark rankings risk becoming more a reflection of gaming the system than actual model capabilities.