Updated: May 22 2024 18:21Meta has recently introduced Chameleon, a family of early-fusion token-based mixed-modal models that can understand and generate images and text in any arbitrary sequence. This groundbreaking development marks a significant step forward in the field of multimodal foundation models, offering new possibilities for AI applications that can seamlessly process and generate both visual and textual information.
What Sets Chameleon Apart?
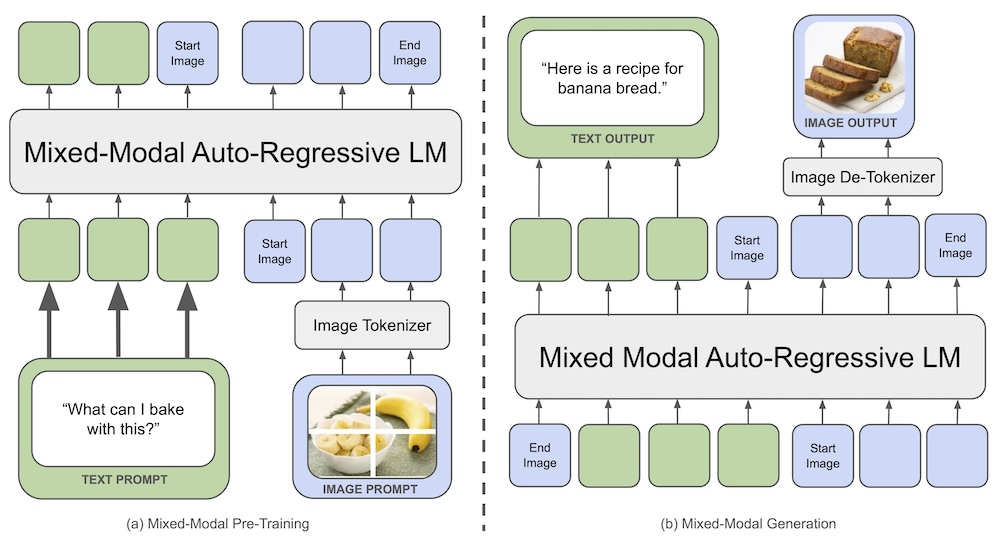
Unlike traditional multimodal models that use separate encoders or decoders for different modalities, Chameleon employs a unified approach using fully token-based representations for both images and text. By quantizing images into discrete tokens, analogous to words in text, Chameleon can apply the same transformer architecture to sequences of both image and text tokens. This early-fusion approach allows for seamless reasoning and generation across modalities.
Key features of Chameleon include:
- Uniform architecture trained from scratch on an interleaved mixture of all modalities (images, text, code)
- Novel modifications to the transformer architecture for stable training in the mixed-modal setting
- Adapted supervised finetuning approaches for strong alignment at scale
Training and Performance
Training early-fusion models like Chameleon presents significant technical challenges in terms of optimization stability and scaling. Meta's researchers addressed these challenges through architectural innovations and training techniques, successfully training Chameleon-34B on 5x the number of tokens as Llama-2.
The training process involved two stages using a dataset of 4.4 trillion tokens of text, image-text combinations, and sequences of interwoven texts and images.
Two versions of Chameleon were trained: one with 7 billion parameters and another with 34 billion parameters. The training session lasted over 5 million hours on Nvidia A100 80GB GPUs. Extensive evaluations demonstrate Chameleon's broad capabilities across a diverse set of tasks:
- State-of-the-art performance on visual question answering and image captioning benchmarks, outperforming models like Flamingo, IDEFICS, and Llava-1.5
- Competitive performance on text-only benchmarks, matching models like Mixtral 8x7B and Gemini-Pro on commonsense reasoning and reading comprehension tasks
- High-quality image generation capabilities
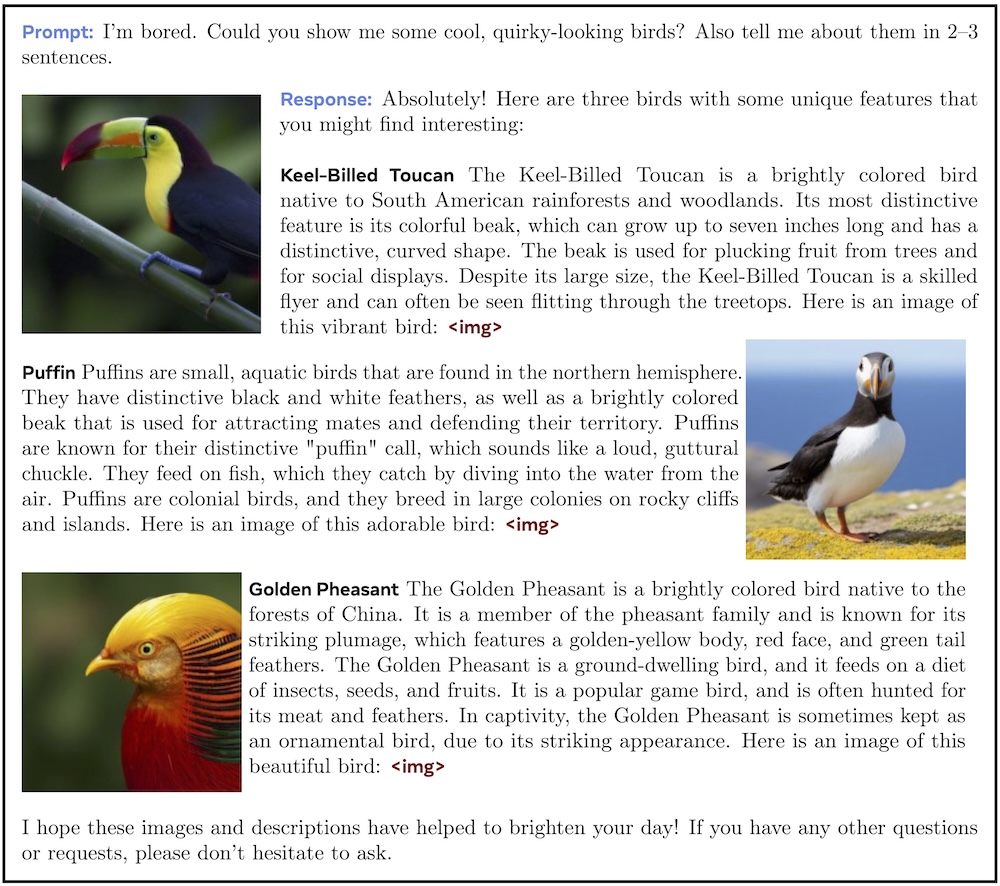
Below is a sample interleaved image and text generation from Chameleon:
Human Evaluation and Mixed-Modal Reasoning
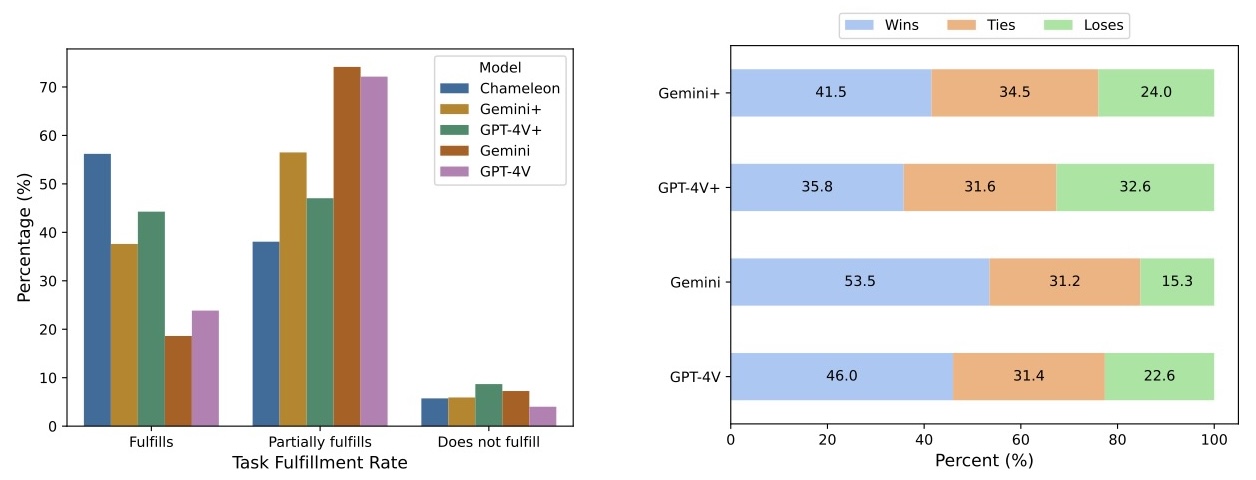
To further assess Chameleon's performance, Meta conducted a large-scale human evaluation experiment measuring the quality of mixed-modal long-form responses to open-ended prompts. Chameleon-34B substantially outperformed strong baselines like Gemini-Pro and GPT-4V, achieving a 60.4% preference rate against Gemini-Pro and a 51.6% preference rate against GPT-4V in pairwise comparisons.
This evaluation highlights Chameleon's unique capabilities in mixed-modal reasoning and generation, setting a new bar for open multimodal foundation models. Here is the performance of Chameleon vs baselines, on mixed-modal understanding and generation on a set of diverse and natural prompts from human annotators. Compared to Gemini and GPT-4V, Chameleon is very competitive when handling prompts that expect interleaving, mixed-modal responses. The images generated by Chameleon are usually relevant to the context, making the documents with interleaving text and images very appealing to users.
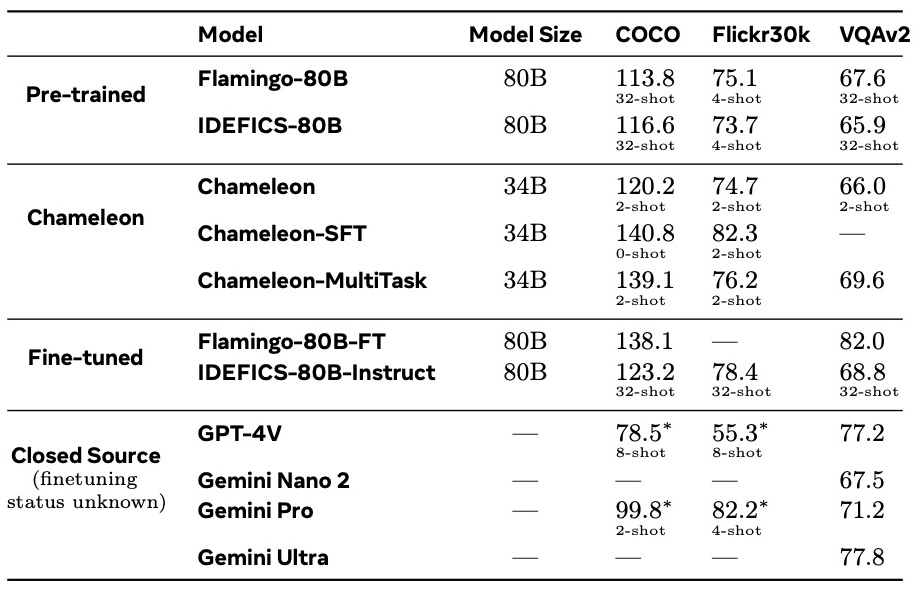
Here is the Chameleon model performances on Image-to-Text capabilities. Chameleon is fairly competitive on both image captioning and VQA tasks. It rivals other models by using much fewer in-context training examples and with smaller model sizes, in both pre-trained and fine-tuned model evaluations.
The Future of Multimodal AI
Chameleon represents a significant milestone in the development of unified foundation models capable of flexibly reasoning over and generating multimodal content. As the AI race continues, with major players like OpenAI, Microsoft, and Google introducing their own advanced models like GPT-3o, Phi-3, and Gemini, Meta's Chameleon stands out for its early-fusion approach and impressive performance across a wide range of tasks.
While it is not yet known when Meta will release Chameleon, the model's potential to enable new AI applications that seamlessly integrate visual and textual information is undeniable.
Full Report:
Chameleon: Mixed-Modal Early-Fusion Foundation ModelsRecent Posts