AI Summary
Researchers from Google Research and Stanford University have developed Video-STaR, an approach that enables AI models to train themselves on video content, enabling them to comprehend and reason about visual information without extensive human annotation. The system uses minimal supervision in the form of basic video labels, allowing large vision language models to progressively enhance their video understanding capabilities through iterative self-training cycles.
Researchers from Google Research and Stanford University have unveiled
Video-STaR (Video Self-Training with augmented Reasoning), a revolutionary approach that enables AI models to train themselves to comprehend and reason about video content. This technological breakthrough, recently published at the International Conference on Learning Representations, represents a significant leap forward in how machines interpret visual information—potentially transforming everything from sports coaching to surgical training.
The Video Understanding Challenge
While large language models have made remarkable strides in text comprehension and generation, their visual counterparts have lagged behind, primarily due to the scarcity of properly labeled video data. The traditional approach of hiring humans to manually describe videos (known as "labeling") is prohibitively expensive and time-consuming, creating a bottleneck in developing truly video-literate AI systems.
Video-STaR elegantly addresses this challenge through an innovative self-training methodology that requires only minimal supervision in the form of basic video labels. By leveraging these existing labels as weak supervision signals, Video-STaR enables large vision language models (LVLMs) to progressively enhance their video understanding capabilities without extensive human annotation.
How Video-STaR Works: Self-Improvement Through Cycles
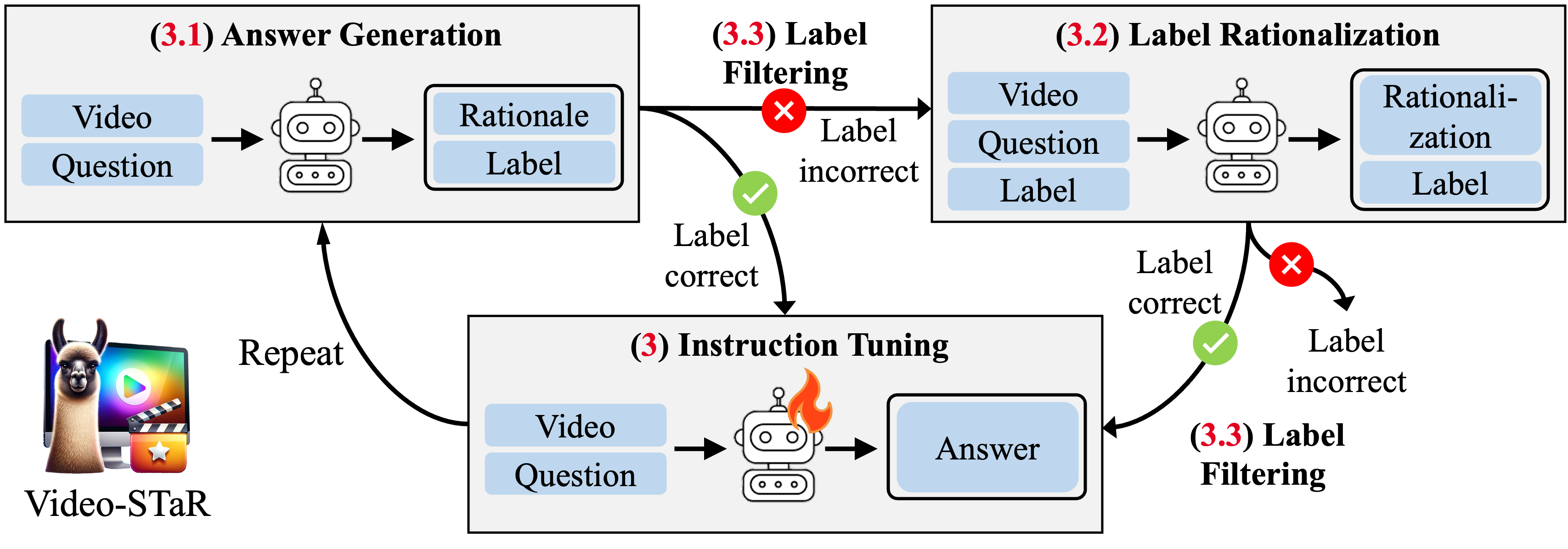
The genius of Video-STaR lies in its iterative self-training process, which follows a three-stage cycle:
- Initial Prompting: A large vision-language model is prompted to generate answers about video content.
- Label Filtering: The system filters these answers, retaining only those that correctly incorporate the original video labels, effectively using these labels as verification.
- Self-Retraining: The model then retrains itself on these filtered, high-quality responses to improve its analytical capabilities.
For videos where the AI initially fails to include the correct labels in its responses, Video-STaR employs a "label rationalization" step. Here, the model is given the video, question, and ground-truth label and asked to explain the reasoning behind the label. This process helps the AI bridge gaps in its understanding.
"In effect, Video-STaR utilizes the existing labels as a form of supervision, a way to check its work," explains Orr Zohar, the paper's first author. "We found that these models learn to reason as an emergent behavior."
After each cycle, the process repeats—with the AI growing increasingly sophisticated in its video comprehension abilities. The beauty of this approach is that it transforms simple labels into rich, detailed understanding without requiring expensive human annotation.
Beyond Simple Description: True Video Understanding
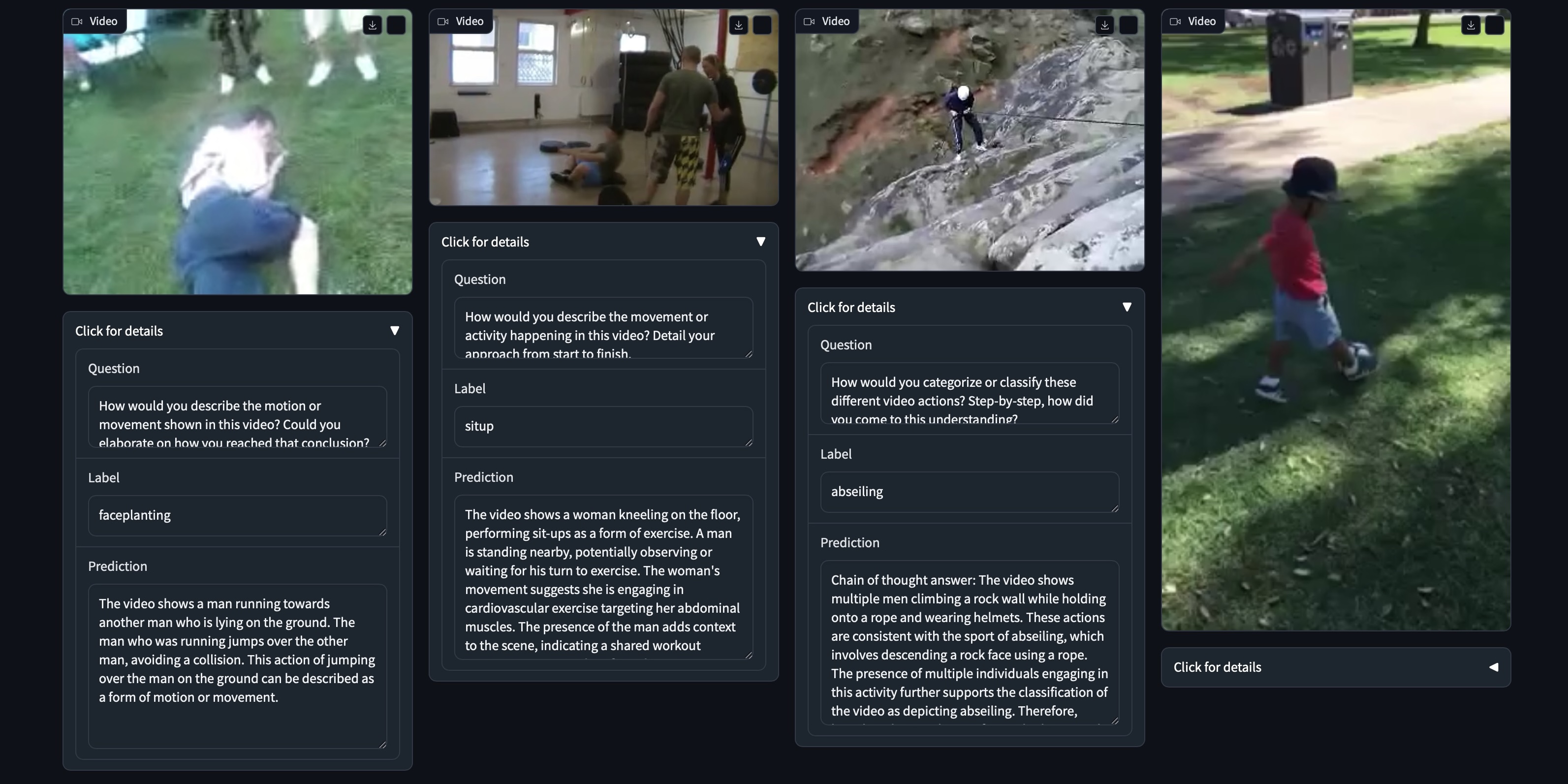
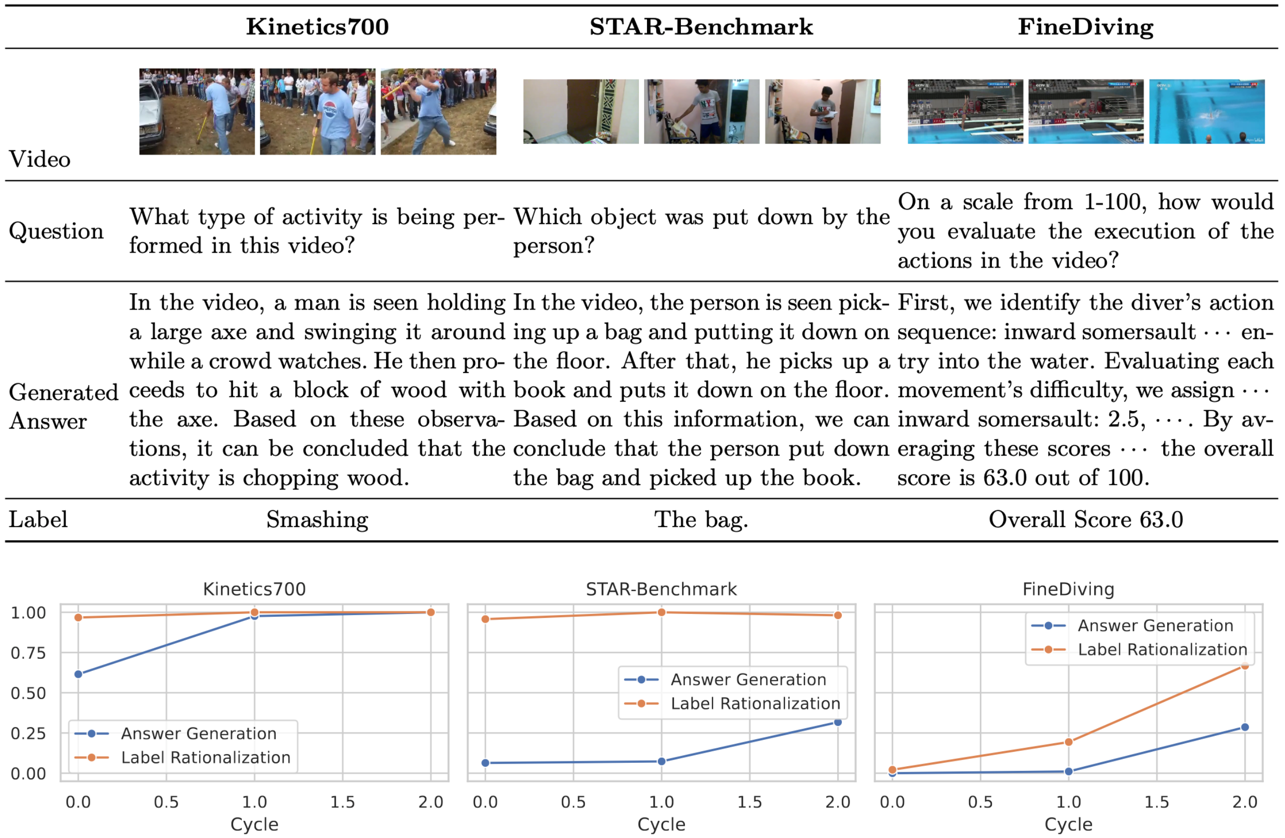
What sets Video-STaR apart from previous approaches is its ability to move beyond mere description to deep reasoning about video content. Traditional video datasets have typically produced simplistic descriptions that fail to capture the nuanced understanding required for meaningful analysis.
In one
demonstration, Video-STaR analyzed footage from a diving competition. Not only did it correctly count the number of somersaults performed and identify the diver's tuck position, but it also evaluated the quality of the entry. Most remarkably, it assigned a difficulty score of 64.68 to a dive that human judges had rated 65.6—showing near-human levels of technical assessment.
This level of detailed comprehension opens doors to applications far beyond what was previously possible with video AI systems.
Real-World Applications: From Sports to Surgery
The potential applications of Video-STaR span numerous fields where visual analysis and feedback are crucial:
- Sports Coaching: AI systems that can analyze a golf swing, tennis serve, or gymnastics routine and provide technical feedback to improve performance.
- Surgical Training: Tools that assess surgeon techniques from video, providing constructive feedback to improve skills and patient outcomes.
- Educational Assessment: AI tutors that can watch student performances of tasks and provide personalized guidance.
- Video Content Analysis: More sophisticated systems for understanding, categorizing, and searching video content.
Professor Serena Yeung-Levy, senior author of the paper and an assistant professor of biomedical data science at Stanford School of Medicine, is particularly excited about medical applications. "For me, one major goal is being able to assess the quality of surgical performance through video analysis," she explains. Such technology could potentially train more surgeons more effectively, ultimately improving patient outcomes.
Building the 'GPT of Video'
The researchers suggest that Video-STaR could enable the creation of a massive, GPT-like dataset for videos—the kind of comprehensive training resource that sparked revolutionary advances in text-based AI. This could be the foundation for developing models with truly general video understanding capabilities.
"The goal is for AI to be able to engage in real conversations about video content, where the user can ask follow-up questions and the model is able to make deeper connections between actions and events in the video content," says Zohar. "That's the next frontier."
Technical Implications and Future Directions
From a technical perspective, Video-STaR represents a significant advance in how we can train sophisticated AI models with limited labeled data. The approach demonstrates that with careful design, AI systems can effectively bootstrap their own learning, using minimal initial guidance to develop much richer understanding.
Future research will likely focus on refining the label filtering process and extending Video-STaR's capabilities to more complex, long-form videos. As these systems improve, we might see AI coaches that can watch hours of gameplay footage to develop tailored training regimens, or medical AI that can review surgical videos to identify best practices and areas for improvement.
Github:
https://github.com/orrzohar/Video-STaRPaper:
VIDEO-STAR: SELF-TRAINING ENABLES VIDEO IN-STRUCTION TUNING WITH ANY SUPERVISIONDataset:
https://huggingface.co/datasets/orrzohar/Video-STaRDemo:
https://huggingface.co/spaces/orrzohar/Video-STaRRecent Posts