AI Summary
Microsoft's phi-3-mini is a 3.8 billion parameter model that can perform tasks like text generation, translation, and coding without requiring massive computational muscle, running directly on smartphones. Its performance is comparable to larger models like ChatGPT and Mixtral, achieving 69% accuracy on the MMLU benchmark with only 1.8GB of memory.
Remember the days when powerful language models were confined to massive data centers and required serious computational muscle? Well, those days are fading fast thanks to the groundbreaking work of the researchers behind phi-3-mini.
What is phi-3-mini?
Imagine having a language model nearly as powerful as ChatGPT, but small enough to run directly on your phone. That's exactly what phi-3-mini brings to the table. This 3.8 billion parameter model is a marvel of efficiency, capable of performing tasks like text generation, translation, and even coding, all while chilling in your pocket.
This Microsoft new language model, phi-3-mini, is a 3.8 billion parameter model trained on a whopping 3.3 trillion tokens. Despite its small size, it’s performance is on par with models such as Mixtral 8x7B and ChatGPT (GPT-3.5). The model achieves 69% on MMLU and 8.38 on MT-bench, and is small enough to be deployed on a phone. The innovation lies entirely in the dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format.
The Secret Sauce: Training Data
So, how did Microsoft achieve this seemingly impossible feat? The answer lies in the training data. Instead of relying solely on massive datasets like many larger models, phi-3-mini utilizes a carefully curated combination of filtered web data and synthetic data. This innovative approach allows the model to learn and adapt with remarkable efficiency, achieving performance on par with models many times its size.
Such a method allows the researchers to reach the level of highly capable models such as GPT-3.5 or Mixtral with only 3.8B total parameters (while Mixtral has 45B total parameters, for example). The training data consists of heavily filtered web data (according to the “educational level”) from various open internet sources, as well as synthetic LLM-generated data.
Pre-training is performed in two disjoint and sequential phases. Phase-1 comprises mostly of web sources aimed at teaching the model general knowledge and language understanding. Phase-2 merges even more heavily filtered web data (a subset used in Phase-1) with some synthetic data that teach the model logical reasoning and various niche skills.
This innovative training methodology is a testament to the power of data-driven machine learning. It shows that by meticulously curating and optimizing the training dataset, researchers can significantly reduce the model’s size without compromising its performance. This is a significant step forward in the field of AI, proving that size isn’t everything when it comes to performance.
Why is This a Big Deal?
To put this in perspective, phi-3-mini achieves a 69% accuracy on the MMLU benchmark. This is comparable to the performance of much larger models trained on conventional datasets. This actually beat the new
Meta Llama 3 8B model that was just released several days ago with a performance at 68.4% on the same MMLU benchmark! The model has also been further aligned for robustness, safety, and chat interactions.
The implications of this development are profound. It demonstrates that with the right training data, we can build highly capable AI assistants that run entirely on personal devices, without relying on the cloud. This enables greater privacy, lower latency, and the ability to operate offline.
Imagine having an AI copilot in your pocket that can engage in open-ended dialogue, answer questions, help with analysis and writing tasks, and even write code - all without sending any data off your device. This is the promise of phi-3-mini and the approach pioneered by the Microsoft team. Some additional benefits are:
- Offline accessibility: Access AI capabilities even in areas with limited connectivity.
- Personalized AI experiences: Fine-tune the model to your specific needs and preferences.
- Enhanced privacy: Keep your data local and avoid sharing sensitive information with external servers.
- Mobile app development: Create smarter apps with advanced language processing capabilities.
Running phi-3-mini on iPhone
Thanks to its small size, phi-3-mini can be quantized to 4-bits so that it only occupies 1.8GB of memory. The quantized model was tested by deploying phi-3-mini on iPhone 14 with A16 Bionic chip running natively on-device and fully offline achieving more than 12 tokens per second. Very impressive performance on iPhone!
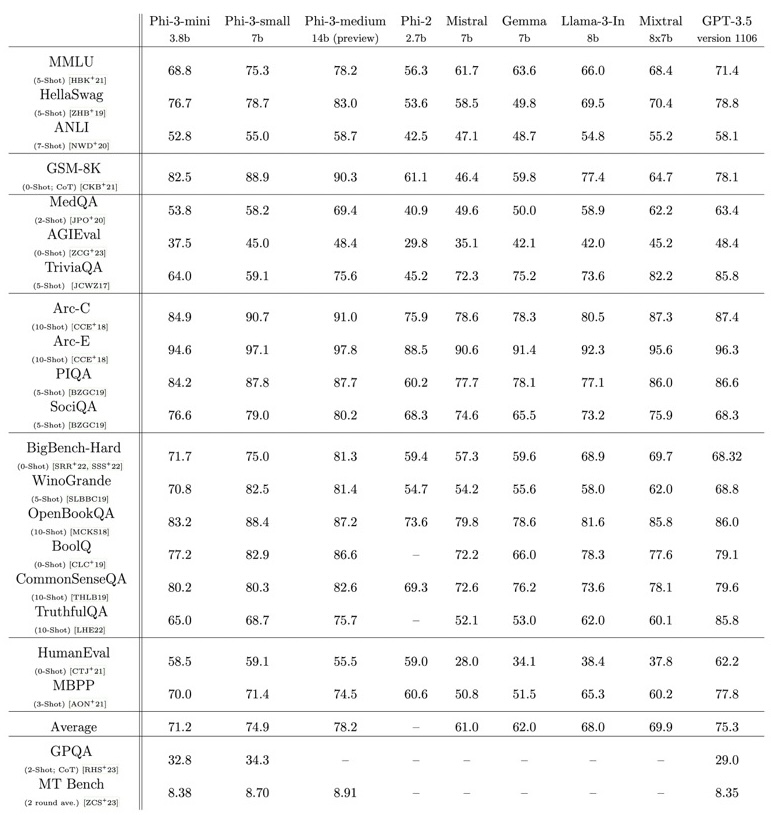
phi-3-mini Benchmark Results Comparison
Here are the results for phi-3-mini on standard open-source benchmarks measuring the model’s reasoning ability (both common sense reasoning and logical reasoning). The table includes comparison with phi-2 [JBA+23], Mistral-7b-v0.1 [JSM+23], Mixtral-8x7b [JSR+24], Gemma 7B [TMH+24], Llama-3-instruct- 8b [AI23], and GPT-3.5. All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable.
The Future is Bright (and Mini small)
Looking ahead, the researchers have also provided a glimpse of what's possible with larger model sizes. The phi-3-small (7B parameters) and phi-3-medium (14B parameters) models, trained on even more data, achieve further jumps in benchmark performance while still being highly efficient.
But perhaps the most exciting aspect is that these gains were achieved solely by improving the training data, without major architectural changes. This suggests that we are still far from hitting the ceiling on language model performance, and that further scaling of high-quality data collection and synthesis may continue to yield impressive results.
phi-3-mini is just the tip of the iceberg. With advancements in data-centric approaches and model optimization, we can expect even more powerful and compact AI models in the future. It opens up new possibilities for personalized, private, and immersive AI interactions on personal devices. And it points the way forward for future developments in efficient and capable language models.
The age of on-device AI assistants has arrived.
Full Report:
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your PhoneRecent Posts